Towards Natural Language Semantic Code Search
Our machine learning scientists have been researching ways to enable the semantic search of code.

This blog post complements a live demonstration on our recently announced site: experiments.github.com
Motivation
Searching code on GitHub is currently limited to keyword search. This assumes either the user knows the syntax, or can anticipate what keywords might be in comments surrounding the code they are looking for. Our machine learning scientists have been researching ways to enable the semantic search of code.
To fully grasp the concept of semantic search, consider the below search query, “ping REST api and return results”:

Note that the demonstrated semantic search returns reasonable results even though there are no keywords in common between the search query and the text (the code & comments found do not contain the words “Ping”, “REST” or “api”)! The implications of augmenting keyword search with semantic search are profound. For example, such a capability would expedite the process of on-boarding new software engineers onto projects and bolster the discoverability of code in general.
In this post, we want to share how we are leveraging deep learning to make progress towards this goal. We also share an open source example with code and data that you can use to reproduce these results!
Introduction
One of the key areas of machine learning research underway at GitHub is representation learning of entities, such as repos, code, issues, profiles and users. We have made significant progress towards enabling semantic search by learning representations of code that share a common vector space as text. For example, consider the below diagram:
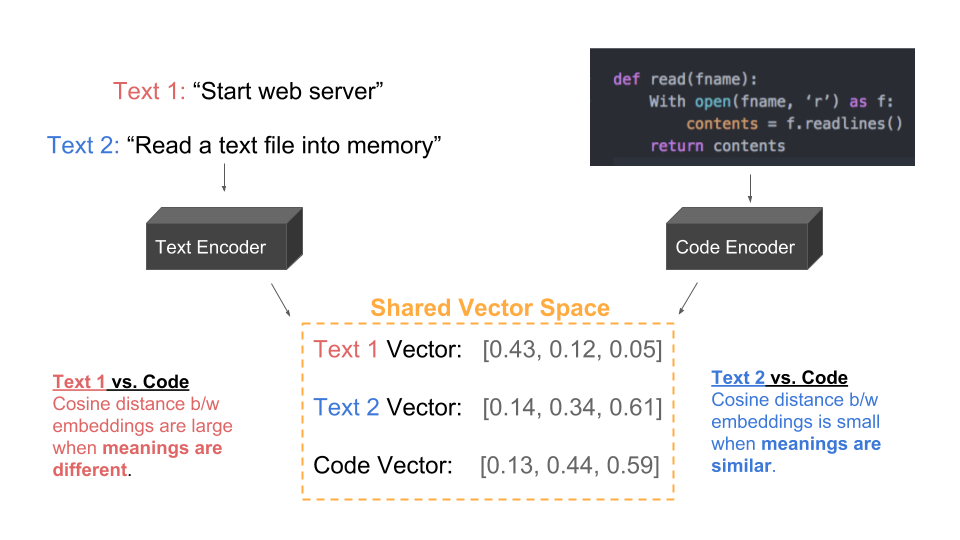
In the above example, Text 2 (blue) is a reasonable description of the code, whereas Text 1 (red) is not related to the code at all. Our goal is to learn representations where (text, code) pairs that describe the same concept are close neighbors, whereas unrelated (text, code) pairs are further apart. By representing text and code in the same vector space, we can vectorize a user’s search query and lookup the nearest neighbor that represents code. Below is a four-part description of the approach we are currently using to accomplish this task:
1. Learning Representations of Code
In order to learn a representation of code, we train a sequence-to-sequence model that learns to summarize code. A way to accomplish this for Python is to supply (code, docstring) pairs where the docstring is the target variable the model is trying to predict. One active area of research for us is incorporating domain specific optimizations like tree-based LSTMs, gated-graph networks and syntax-aware tokenization. Below is a screenshot that showcases the code summarizer model at work. In this example, there are two python functions supplied as input, and in both cases the model produces a reasonable summary of the code as output:
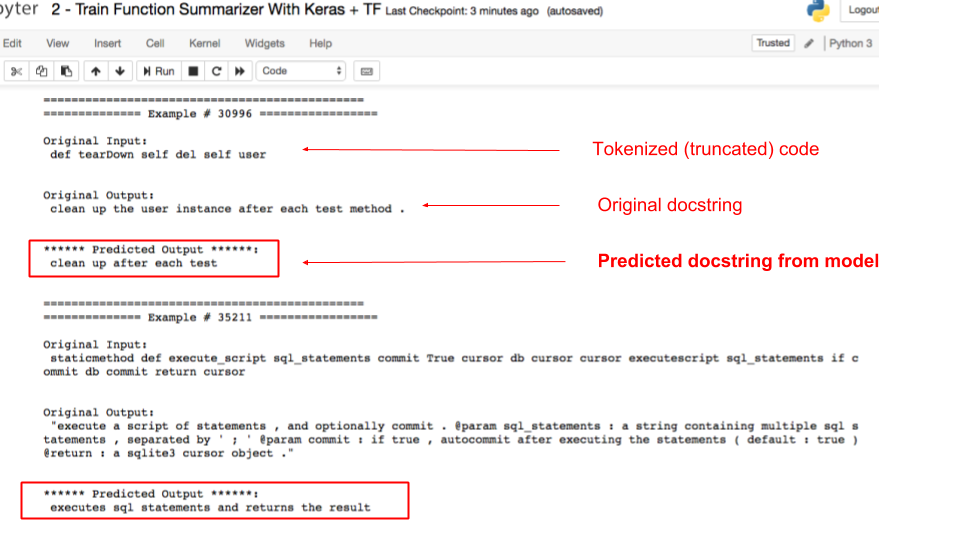
It should be noted that in the above examples, the model produces the summary by using the entire code blob, not merely the function name.
Building a code summarizer is a very exciting project on its own, however, we can utilize the encoder from this model as a general purpose feature extractor for code. After extracting the encoder from this model, we can fine-tune it for the task of mapping code to the vector space of natural language.
We can evaluate this model objectively using the BLEU score. Currently we have been able to achieve a BLEU score of 13.5 on a holdout set of python code, using the fairseq-py library for sequence to sequence models.
2. Learning Representations of Text Phrases
In addition to learning a representation for code, we needed to find a suitable representation for short phrases (like sentences found in Python docstrings). Initially, we experimented with the Universal Sentence Encoder, a pre-trained encoder for text that is available on TensorFlow Hub. While the embeddings from worked reasonably well, we found that it was advantageous to learn embeddings that were specific to the vocabulary and semantics of software development. One area of ongoing research involves evaluating different domain-specific corpuses for training our own model, ranging from GitHub issues to third party datasets.
To learn this representation of phrases, we trained a neural language model by leveraging the fast.ai library. This library gave us easy access to state of the art architectures such as AWD LSTMs, and to techniques such as cyclical learning rates with random restarts. We extracted representations of phrases from this model by summarizing the hidden states using the concat pooling approach found in this paper.
One of the most challenging aspects of this exercise was to evaluate the quality of these embeddings. We are currently building a variety of downstream supervised tasks similar to those outlined here that will aid us in evaluating the quality of these embeddings objectively. In the meantime, we sanity check our embeddings by manually examining the similarity between similar phrases. The below screenshot illustrates examples where we search the vectorized docstrings for similarity against user-supplied phrases:
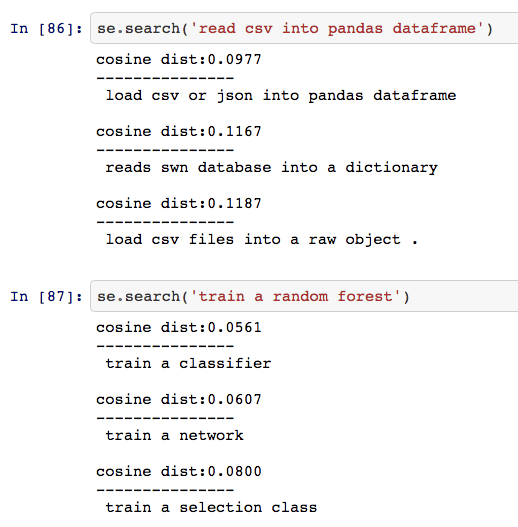
3. Mapping Code Representations To The Same Vector-Space as Text
Next, we map the code representations we learned from the code summarization model (part 1) to the vector space of text. We accomplish this by fine-tuning the encoder of this model. The inputs to this model are still code blobs, however the target variable the model is now the vectorized version of docstrings. These docstrings are vectorized using the approach discussed in the previous section.
Concretely, we perform multi-dimensional regression with cosine proximity loss to bring the hidden state of the encoder into the same vector-space as text.
We are actively researching alternate approaches that directly learn a joint vector space of code and natural language, borrowing from some ideas outlined here.
4. Creating a Semantic Search System
Finally, after successfully creating a model that can vectorize code into the same vector-space as text, we can create a semantic search mechanism. In its most simple form, we can store the vectorized version of all code in a database, and perform nearest neighbor lookups to a vectorized search query.
Another active area of our research is determining the best way to augment existing keyword search with semantic results and how to incorporate additional information such as context and relevance.
Furthermore, we are actively exploring ways to evaluate the quality of search results that will allow us to iterate quickly on this problem. We leave these topics for discussion in a future blog post.
Summary
The below diagram summarizes all the steps in our current semantic-search workflow:
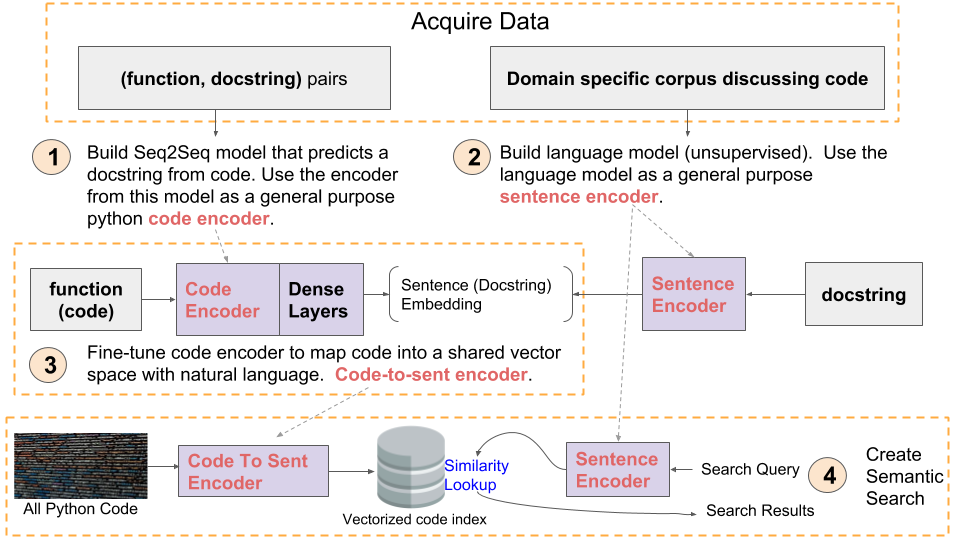
We are exploring ways to improve almost every component of this approach, including data preparation, model architecture, evaluation procedures, and overall system design. What is described in this blog post is only a minimal example that scratches the surface.
Open Source Examples
Our open-source end-to-end tutorial contains a detailed walkthrough of the approach outlined in this blog, along with code and data you can use to reproduce the results.
This open source example (with some modifications) is also used as a tutorial for the kubeflow project, which is implemented here.
Limitations and Intended Use Case(s)
We believe that semantic code search will be most useful for targeted searches of code within specific entities such as repos, organizations or users as opposed to general purpose “how to” queries. The live demonstration of semantic code search hosted on our recently announced Experiments site does not allow users to perform targeted searches of repos. Instead, this demonstration is designed to share a taste of what might be possible and searches only a limited, static set of python code.
Furthermore, like all machine learning techniques, the efficacy of this approach is limited by the training data used. For example, the data used to train these models are (code, docstring) pairs. Therefore, search queries that closely resemble a docstring have the greatest chance of success. On the other hand, queries that do not resemble a docstring or contain concepts for which there is little data may not yield sensible results. Therefore, it is not difficult to challenge our live demonstration and discover the limitations of this approach. Nevertheless, our initial results indicate that this is an extremely fruitful area of research that we are excited to share with you.
There are many more use cases for semantic code search. For example, we could extend the ideas presented here to allow users to search for code using the language of their choice (French, Mandarin, Arabic, etc.) across many different programming languages simultaneously.
Get In Touch
This is an exciting time for the machine learning research team at GitHub and we are looking to expand. If our work interests you, please get in touch!
Contributors


Written by

Related posts

Automate your project with GitHub Models in Actions
Learn how to integrate AI features with GitHub Models directly in GitHub Actions workflows.
Onboarding your AI peer programmer: Setting up GitHub Copilot coding agent for success
Learn how to configure Copilot coding agent’s environment, optimize project structure, use custom instructions, and extend its capabilities with MCP servers.

A practical guide on how to use the GitHub MCP server
Upgrade from a local MCP Docker image to GitHub’s hosted server and automate pull requests, continuous integration, and security triage in minutes — no tokens required.