Scientist: Measure Twice, Cut Once
Today we’re releasing Scientist 1.0 to help you rewrite critical code with confidence. As codebases mature and requirements change, it is inevitable that you will need to replace or rewrite…
Today we’re releasing Scientist 1.0 to help you rewrite critical code with confidence.
As codebases mature and requirements change, it is inevitable that you will need to replace or rewrite a part of your system. At GitHub, we’ve been lucky to have many systems that have scaled far beyond their original design, but eventually there comes a point when performance or extensibility break down and we have to rewrite or replace a large component of our application.
Problem
A few years ago when we were faced with the task of rewriting one of the most critical systems in our application — the permissions code that controls access and membership to repositories, teams, and organizations — we began looking for a way to make such a large change and have confidence in its correctness.
There is a fairly common architectural pattern for making large-scale changes known as Branch by Abstraction. It works by inserting an abstraction layer around the code you plan to change. The abstraction simply delegates to the existing code to begin with. Once you have the new code in place, you can flip a switch in the abstraction to begin substituting the new code for the old.
Using abstractions in this way is a great way to create a chokepoint for calls to a particular code path, making it easy to switch over to the new code when the time comes, but it doesn’t really ensure that the behavior of the new system will match the old system — just that the new system will be called in all places where the old system was called. For such a critical piece of our system architecture, this pattern only fulfilled half of the requirements. We needed to ensure not only that the new system would be used in all places that the old system was, but also that its behavior would be correct and match what the old system did.
Why tests aren’t enough
If you want to test correctness, you just write some tests for your new system, right? Well, not quite. Tests are a good place to start verifying the correctness of a new system as you write it, but they aren’t enough. For sufficiently complicated systems, it is unlikely you will be able to cover all possible cases in your test suite. If you do, it will be a large, slow test suite that slows down development considerably.
There’s also a more concerning reason not to rely solely on tests to verify correctness: Since software has bugs, given enough time and volume, your data will have bugs, too. Data quality is the measure of how buggy your data is. Data quality problems may cause your system to behave in unexpected ways that are not tested or explicitly part of the specifications. Your users will encounter this bad data, and whatever behavior they see will be what they come to rely on and consider correct. If you don’t know how your system works when it encounters this sort of bad data, it’s unlikely that you will design and test the new system to behave in the way that matches the legacy behavior. So, while test coverage of a rewritten system is hugely important, how the system behaves with production data as the input is the only true test of its correctness compared to the legacy system’s behavior.
Enter Scientist
We built Scientist to fill in that missing piece and help test the production data and behavior to ensure correctness. It works by creating a lightweight abstraction called an experiment around the code that is to be replaced. The original code — the control — is delegated to by the experiment abstraction, and its result is returned by the experiment. The rewritten code is added as a candidate to be tried by the experiment at execution time. When the experiment is called at runtime, both code paths are run (with the order randomized to avoid ordering issues). The results of both the control and candidate are compared and, if there are any differences in that comparison, those are recorded. The duration of execution for both code blocks is also recorded. Then the result of the control code is returned from the experiment.
From the caller’s perspective, nothing has changed. But by running and comparing both systems and recording the behavior mismatches and performance differences between the legacy system and the new one, you can use that data as a feedback loop to modify the new system (or sometimes the old!) to fix the errors, measure, and repeat until there are no differences between the two systems. You can even start using Scientist before you’ve fully implemented the rewritten system by telling it to ignore experiments that mismatch due to a known difference in behavior.
The diagram below shows the happy path that experiments follow:
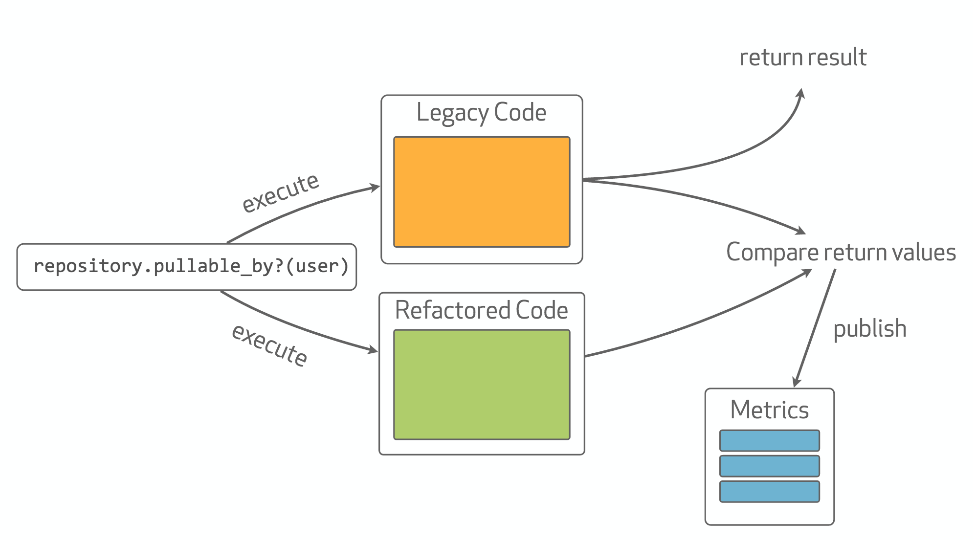
Happy paths are only part of a system’s behavior, though, so Scientist can also handle exceptions. Any exceptions encountered in either the control or candidate blocks will be recorded in the experiments observations. An exception in the control will be re-raised at the end of the experiment since this is the “return value” of that block; exceptions in candidate blocks will not be raised since that would create an unexpected side-effect of the experiment. If the candidate and control blocks raise the same exception, this is considered a match since both systems are behaving the same way.
Example
Let’s say we have a method to determine whether a repository can be pulled by a particular user:
class Repository
def pullable_by?(user)
self.is_collaborator?(user)
end
endBut the is_collaborator? method is very inefficient and does not perform well, so you have written a new method to replace it:
class Repository
def has_access?(user)
...
end
endTo declare an experiment, wrap it in a science block and name your experiment:
def pullable_by?(user)
science "repository.pullable-by" do |experiment|
...
end
endDeclare the original body of the method to be the control branch — the branch to be returned by the entire science block once it finishes running:
def pullable_by?(user)
science "repository.pullable-by" do |experiment|
experiment.use { is_collaborator?(user) }
end
endThen specify the candidate branch to be tried by the experiment:
def pullable_by?(user)
science "repository.pullable-by" do |experiment|
experiment.use { is_collaborator?(user) }
experiment.try { has_access?(user) }
end
endYou may also want to add some context to the experiment to help debug potential mismatches:
def pullable_by?(user)
science "repository.pullable-by" do |experiment|
experiment.context :repo => id, :user => user.id
experiment.use { is_collaborator?(user) }
experiment.try { has_access?(user) }
end
endEnabling
By default, all experiments are enabled all of the time. Depending on where you are using Scientist and the performance characteristics of your application, this may not be safe. To change this default behavior and have more control over when experiments run, you’ll need to create your own experiment class and override the enabled? method. The code sample below shows how to override enabled? to enable each experiment a percentage of the time:
class MyExperiment
include ActiveModel::Model
include Scientist::Experiment
attr_accessor :percentage
def enabled?
rand(100) < percentage
end
endYou’ll also need to override the new method to tell Scientist create new experiments with your class rather than the default experiment implementation:
module Scientist::Experiment
def self.new(name)
MyExperiment.new(name: name)
end
endPublishing results
Scientist is not opinionated about what you should do with the data it produces; it simply makes the metrics and results available and leaves it up to you to decide how and whether to store it. Implement the publish method in your experiment class to record metrics and store mismatches. Scientist passes an experiment’s result to this method. A Scientist::Result contains lots of useful information about the experiment such as:
- whether an experiment matched, mismatched, or was ignored
- the results of the control and candidate blocks if there was a difference
- any additional context added to the experiment
- the duration of the candidate and control blocks
At GitHub, we use Brubeck and Graphite to record metrics. Most experiments use Redis to store mismatch data and additional context. Below is an example of how we publish results:
class MyExperiment
def publish(result)
name = result.experiment_name
$stats.increment "science.#{name}.total"
$stats.timing "science.#{name}.control", result.control.duration
$stats.timing "science.#{name}.candidate", result.candidates.first.duration
if result.mismatched?
$stats.increment "science.#{name}.mismatch"
store_mismatch_data(result)
end
end
end
def store_mismatch_data(result)
payload = {
:name => name,
:context => context,
:control => observation_payload(result.control),
:candidate => observation_payload(result.candidates.first),
:execution_order => result.observations.map(&:name)
}
Redis.lpush "science.#{name}.mismatch", payload
...
end
endBy publishing this data, we get graphs that look like this:
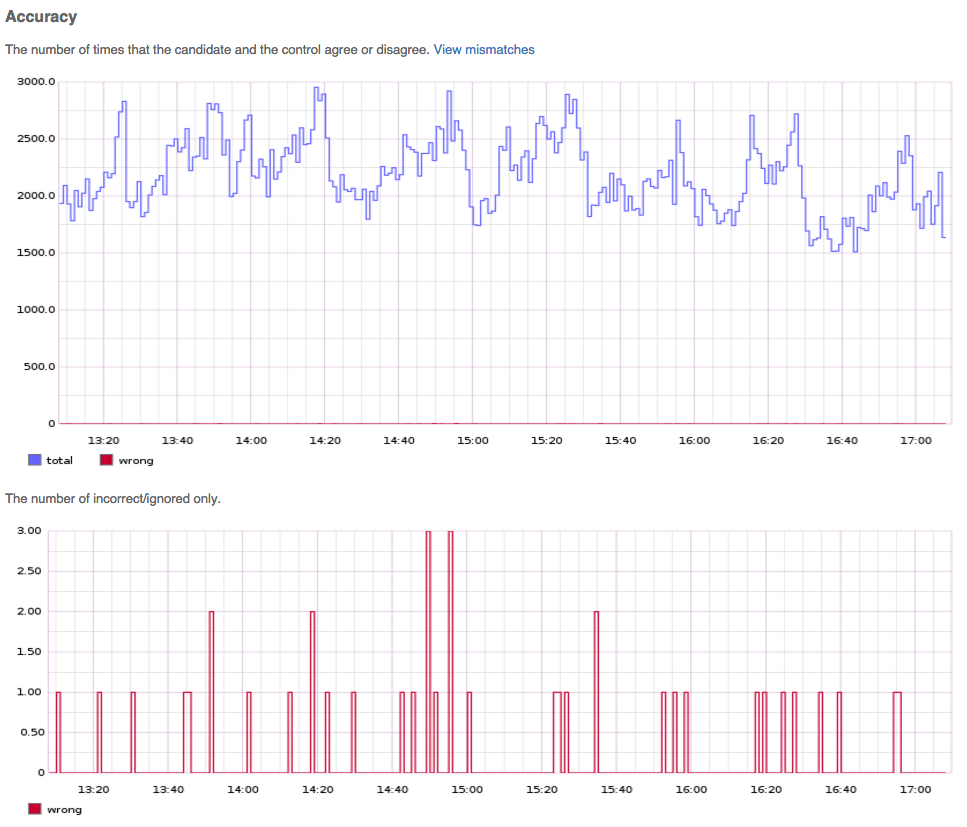
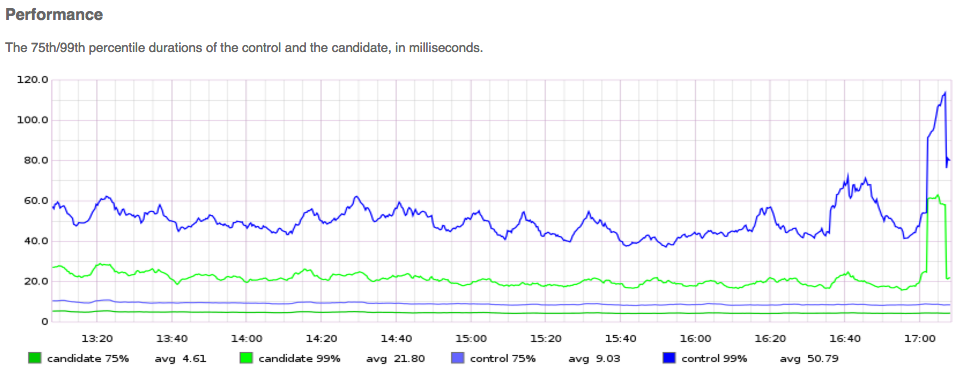
And mismatch data like:
{
context:
repo: 3
user: 1
name: "repository.pullable-by"
execution_order: ["candidate", "control"]
candidate:
duration: 0.0015689999999999999
exception: nil
value: true
control:
duration: 0.000735
exception: nil
value: false
}Using the data to correct the system
Once you have some mismatch data, you can begin investigating individual mismatches to see why the control and candidate aren’t behaving the same way. Usually you’ll find that the new code has a bug or is missing a part of the behavior of the legacy code, but sometimes you’ll find that the bug is actually in the legacy code or in your data. After the source of the error has been corrected, you can start the experiment again and repeat this process until there are no more mismatches between the two code paths.
Finishing an experiment
Once you are able to conclude with reasonable confidence that the control and candidate are behaving the same way, it’s time to wrap up your experiment! Ending an experiment is as simple as disabling it, removing the science code and control implementation, and replacing it with the candidate implementation.
def pullable_by?(user)
has_access?(user)
endCaveats
There are a few cases where Scientist is not an appropriate tool to use. The most important caveat is that Scientist is not meant to be used for any code that has side-effects. A candidate code path that writes to the same database as the control, invalidates a cache, or otherwise modifies data that affects the original, production behavior is dangerous and incorrect. For this reason, we only use Scientist on read operations.
You should also be mindful that you take a performance hit using Scientist in production. New experiments should be introduced slowly and carefully and their impact on production performance should be closely monitored. They should run for just as long as is necessary to gain confidence rather than being left to run indefinitely, especially for expensive operations.
Conclusion
We make liberal use of Scientist for a multitude of problems at GitHub. This development pattern can be used for something as small as a single method or something as large as an external system. The Move Fast and Fix Things post is a great example of a short rewrite made easier with Scientist. Over the last few years we’ve also used Scientist for projects such as:
- a large, multi-year-long rewrite and clean up of our permission code
- switching to a new code search cluster
- optimizing queries — this allows us to ensure not only better performance of the new query, but that it is still correct and doesn’t unintentionally return more or less or different data
- refactoring risky parts of the codebase — to ensure no unintentional changes have been introduced
If you’re about to make a risky change to your Ruby codebase, give the Scientist gem a try and see if it can help make your work easier. Even if Ruby isn’t your language of choice, we’d still encourage you to apply Scientist’s experiment pattern to your system. And of course we would love to hear about any open source libraries you build to accomplish this!
Written by

Related posts

Why developer expertise matters more than ever in the age of AI
AI can help you code faster, but knowing why the code works—and sharpening your human-in-the-loop skills—is what makes you a great developer.
How to create issues and pull requests in record time on GitHub
Learn how to spin up a GitHub Issue, hand it to Copilot, and get a draft pull request in the same workflow you already know.
The difference between coding agent and agent mode in GitHub Copilot
We’ll decode these two tools—and show you how to use them both to work more efficiently.