Move Fast and Fix Things
Anyone who has worked on a large enough codebase knows that technical debt is an inescapable reality: The more rapidly an application grows in size and complexity, the more technical…
Anyone who has worked on a large enough codebase knows that technical debt is an inescapable reality: The more rapidly an application grows in size and complexity, the more technical debt is accrued. With GitHub’s growth over the last 7 years, we have found plenty of nooks and crannies in our codebase that are inevitably below our very best engineering standards. But we’ve also found effective and efficient ways of paying down that technical debt, even in the most active parts of our systems.
At GitHub we try not to brag about the “shortcuts” we’ve taken over the years to scale our web application to more than 12 million users. In fact, we do quite the opposite: we make a conscious effort to study our codebase looking for systems that can be rewritten to be cleaner, simpler and more efficient, and we develop tools and workflows that allow us to perform these rewrites efficiently and reliably.
As an example, two weeks ago we replaced one of the most critical code paths in our infrastructure: the code that performs merges when you press the Merge Button in a Pull Request. Although we routinely perform these kind of refactorings throughout our web app, the importance of the merge code makes it
an interesting story to demonstrate our workflow.
Merges in Git
We’ve talked at length in the past about the storage model that GitHub uses for repositories in our platform and our Enterprise offerings. There are many implementation details that make this model efficient in both performance and disk usage, but the most relevant one here is the fact that repositories are always stored “bare”.
This means that the actual files in the repository (the ones that you would see on your working directory when you clone the repository) are not actually available on disk in our infrastructure: they are compressed and delta’ed inside packfiles.
Because of this, performing a merge in a production environment is a nontrivial endeavour. Git knows several merge strategies, but the recursive merge strategy that you’d get by default when using git merge to merge two branches in a local repository assumes the existence of a working tree for the repository, with all the files checked out on it.
The workaround we developed in the early days of GitHub for this limitation is effective, but not particularly elegant: instead of using the default git-merge-recursive strategy, we wrote our own merge strategy based on the original one that Git used back in the day: git-merge-resolve. With some tweaking, the old strategy can be adapted to not require an actual checkout of the files on disk.
To accomplish this, we wrote a shell script that sets up a temporary working directory, in which the merge engine performs content-level merges. Once these merges are complete, the files are written back into the original repository, together with the resulting trees.
The core of this merge helper looks like this:
git read-tree -i -m --aggressive $merge-base $head1 $head2
git merge-index git-merge-one-file -a || exit 2
git write-tree >&3This merges two trees in a bare repository rather effectively, but it has several shortcomings:
- It creates temporary directories on disk; hence, it needs to clean up after
itself. - It creates a temporary index on disk, which also requires cleanup.
- It is not particularly fast, despite Git’s highly optimized merge engine:
the oldgit-merge-one-filescript spawns several processes for each file
that needs to be merged. The need to use disk as temporary scratch space
also acts as a bottleneck. - It doesn’t have the exact same behavior as
git mergein a Git
client, because we’re using an outdated merge strategy (as opposed to the
recursive merge strategy thatgit mergenow performs by default).
Merges in libgit2
libgit2 is the sharpest weapon we own to fight any Git-related technical debt in our platform. Building a web service around Git is notoriously hard, because the tooling of the Core Git project has been designed around local command-line usage, and less thought has been put on the use case of running Git operations on the server-side.
With these limitations in mind, five years ago we began the development of libgit2, a re-implementation of most of Git’s low level APIs as a library that could be linked and used directly within a server-side process. I personally led the development of libgit2 for the first 3 years of its existence, although right now the library is in the very capable hands of Carlos Martín and Ed Thomson. It has also gained a lot of traction, with a solid stream of external contributions from other companies that also use it to build
Git infrastructure — particularly our friends at Microsoft, who use it to implement all the Git functionality in Visual Studio.
Despite being a C library, libgit2 contains many powerful abstractions to accomplish complex tasks that Git simply cannot do. One of these features are indexes that exist solely in memory and allow work-tree related operations to be performed without an actual working directory. Based on this abstraction, Ed Thomson implemented an incredibly elegant merge engine as one of his first contributions to the library.
With the in-memory index, libgit2 is capable of merging two trees in a repository without having to check out any of their files on disk. On paper, this implementation is ideal for our use case: it is faster, simpler and more efficient than what we’re currently doing with Git. But it is also a serious amount of new code that ought to replace some of the most critical functionality of our website.
Trust issues
In this specific case, although I had thoroughly reviewed the merge implementation as libgit2’s maintainer, it would be reckless to assume it to be production ready. In fact, it would be even more reckless if I had written the whole implementation myself. The merge process is incredibly complex, in both the old and the new implementations, and GitHub operates at a scale where seemingly obscure “corner cases” will always happen by default. When it comes to user’s data, ignoring corner cases is not an option.
To make matters worse, this is not a new feature; this is a replacement for an existing feature which worked with no major issues (besides the technical debt and poor performance characteristics). There is no room for bugs or performance regressions. The switch-over needs to be flawless and —just as importantly— it needs to be efficient.
Efficiency is fundamental in these kind of projects because even with the performance improvements they entail, it becomes hard to justify the time investment if we cannot wrap up the refactoring in a tight timeframe.
Without a clear deadline and a well defined workflow, it’s easy to waste weeks of work rewriting code that will end up being buggier and less reliable than the old implementation. To prevent this, and to make these rewrites sustainable, we need to be able to perform them methodically in a virtually flawless fashion. This is a hard problem to tackle.
Fortunately, this challenge is not unique to the systems code in GitHub. All of our engineering teams are just as concerned with code quality issues as we are, and for rewrites that interface with our main Rails app (like in this specific example, the PR merge functionality), our Core Application team has built extensive tooling that makes this extremely complicated process tenable.
Preparing for an experiment
The first step of the rollout process of the new implementation was to implement the RPC calls for the new functionality. All the Git-related operations in our platform happen through a service called GitRPC, which intelligently routes the request from the frontend servers and performs the operation on the fileserver where the corresponding repository is stored.
For the old implementation, we were simply using a generic git_spawn RPC call, which runs the corresponding Git command (in this case, the script for our custom merge strategy) and returns the stdout, stderr and exit code to the frontend. The fact that we were using a generic spawn, instead of a specialized RPC call that performed the whole operation on the fileserver and returned the result, was another sign of technical debt: our main application required its own logic to parse and understand the results of a merge.
Hence, for our new implementation, we wrote a specific create_merge_commit call, which would perform the merge operation in-memory and in-process on the fileserver side. The RPC service running on our fileservers is written in Ruby, just like our main Rails application, so all the libgit2 operations are actually performed using Rugged, the Ruby bindings for libgit2 which we develop in house.
Thanks to the design of Rugged, which turns libgit2’s low level APIs into usable interfaces in Ruby-land, writing the merge implementation is straightforward:
def create_merge_commit(base, head, author, commit_message)
base = resolve_commit(base)
head = resolve_commit(head)
commit_message = Rugged.prettify_message(commit_message)
merge_base = rugged.merge_base(base, head)
return [nil, "already_merged"] if merge_base == head.oid
ancestor_tree = merge_base && Rugged::Commit.lookup(rugged, merge_base).tree
merge_options = {
:fail_on_conflict => true,
:skip_reuc => true,
:no_recursive => true,
}
index = base.tree.merge(head.tree, ancestor_tree, merge_options)
return [nil, "merge_conflict"] if (index.nil? || index.conflicts?)
options = {
:message => commit_message,
:committer => author,
:author => author,
:parents => [base, head],
:tree => index.write_tree(rugged)
}
[Rugged::Commit.create(rugged, options), nil]
endAlthough GitRPC runs as a separate service on our fileservers, its source code is part of our main repository, and it is usually deployed in lockstep with the main Rails application in the frontends. Before we could start switching over the implementations, we merged and deployed the new RPC call to production, even though it was not being used anywhere yet.
We refactored the main path for merge commit creation in the Rails app to extract the Git-specific functionality into its own method. Then we implemented a second method with the same signature as the Git-based code, but this one performing the merge commit through Rugged/libgit2.
Since deploying to production at GitHub is extremely straightforward (we perform about 60 deploys of our main application every day), I deployed the initial refactoring right away. That way we needn’t worry about a potential gap in our extensive test suite: if the trivial refactoring introduced any issues in the existing behavior, they would be quickly spotted by deploying to a small percentage of the machines serving production traffic. Once I deemed the refactoring safe, it was fully deployed to all the frontend machines and merged into the mainline.
Once we have the two code paths ready in our main application and in the RPC server, we can let the magic begin: we will be testing and benchmarking the two implementations, in production but without affecting in any way our existing users, thanks to the power of Scientist.
Scientist is a library for testing refactorings, rewrites and performance improvements in Ruby. It was originally part of our Rails application, but we’ve extracted and open-sourced it. To start our testing with Scientist, we declare an experiment and set the old code path as a control sample and the new code path as a candidate.
def create_merge_commit(author, base, head, options = {})
commit_message = options[:commit_message] || "Merge #{head} into #{base}"
now = Time.current
science "create_merge_commit" do |e|
e.context :base => base.to_s, :head => head.to_s, :repo => repository.nwo
e.use { create_merge_commit_git(author, now, base, head, commit_message) }
e.try { create_merge_commit_rugged(author, now, base, head, commit_message) }
end
endOnce this trivial change is in place, we can safely deploy it to production machines. Since the experiment has not been enabled yet, the code will work just as it did before: the control (old code path) will be executed and its result returned directly to the user. But with the experiment code deployed in production, we’re one button click away from making SCIENCE! happen.
The SCIENCE! behind a merge commit
The first thing we do when starting an experiment is enable it for a tiny fraction (1%) of all the requests. When an experiment “runs” in a request, Scientist does many things behind the scenes: it runs the control and the candidate (randomizing the order in which they run to prevent masking bugs or performance regressions), stores the result of the control and returns it to the user, stores the result of the candidate and swallows any possible exceptions (to ensure that bugs or crashes in the new code cannot possibly impact the user), and compares the result of the control against the candidate, logging exceptions or mismatches in our Scientist web UI.
The core concept of Scientist experiments is that even if the new code path crashes, or gives a bad result, this will not affect users, because they always receive the result of the old code.
With a fraction of all requests running the experiment, we start getting valuable data. Running an experiment at 1% is useful to catch the obvious bugs and crashes in the new code: we can visualize the performance graph to see if we’re heading in a good direction, perf-wise, and we can eyeball the mismatches graph to see if the new code is more-or-less doing the right thing. Once these problems are solved, we increase the frequency of experiments to start catching the actual corner cases.
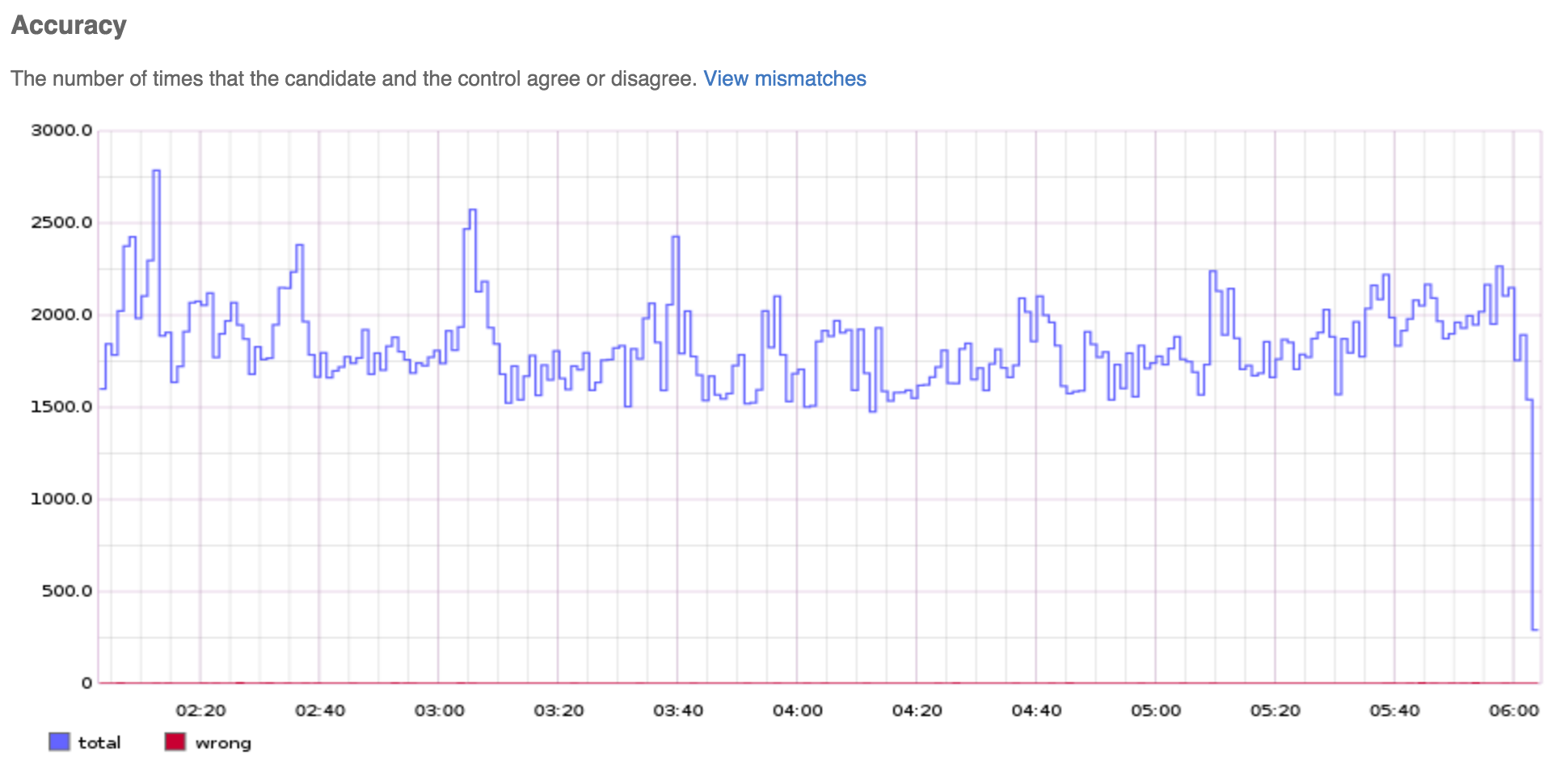
Shortly after the deploy, the accuracy graph shows that experiments are
being run at the right frequency and that mismatches are very few.
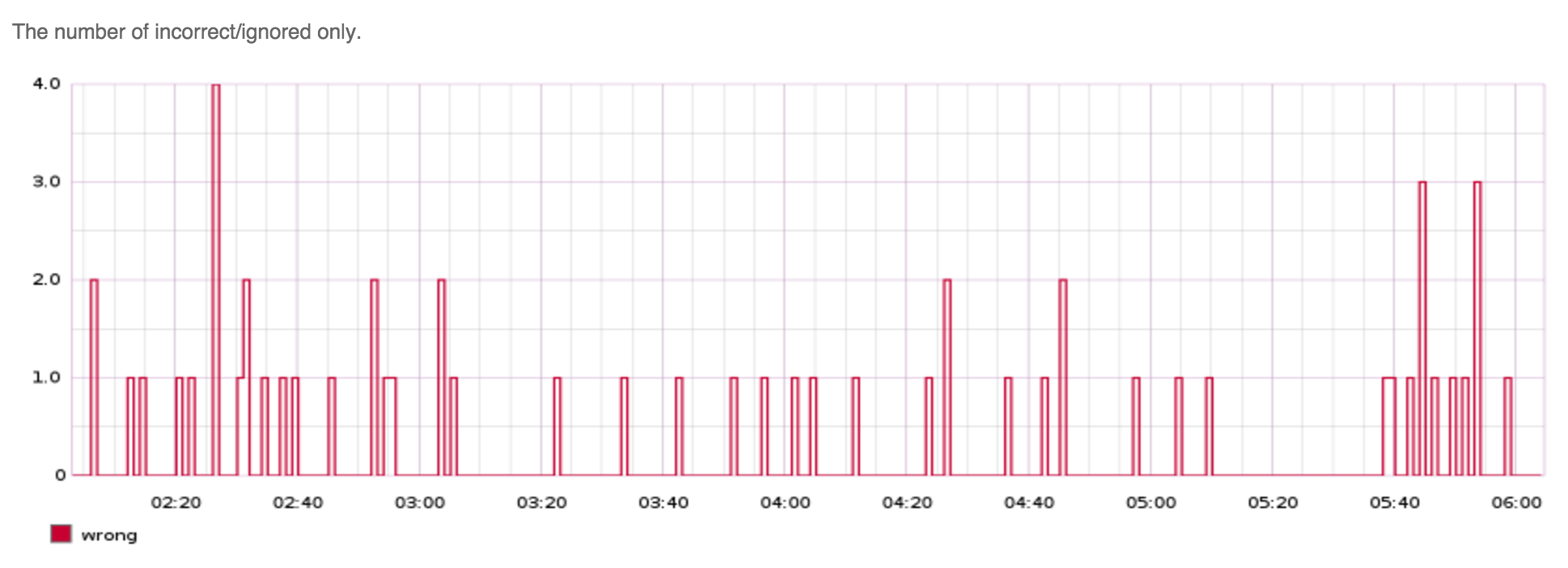
Graphing the errors/mismatches on their own shows their frequency in more
detail. Our tooling captures metadata all these mismatches so they can be
analyzed later.
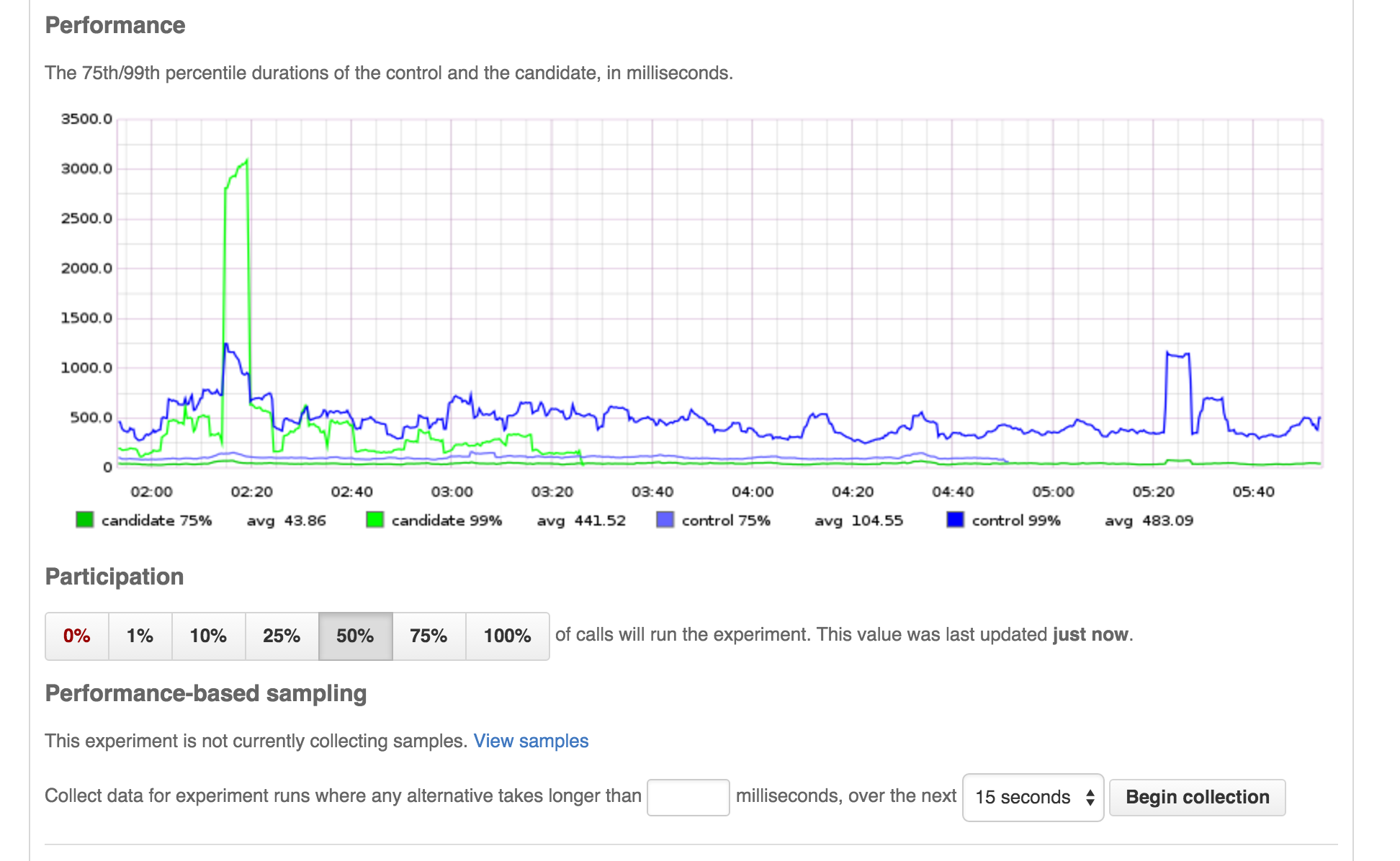
Although it’s too early to tell, shortly after the initial deploy the
performance characteristics look extremely promising. The vertical axis is
time, in milliseonds. Percentiles for the old and new code are shown in blue
and green, respectively.
The main thing we noticed looking at experiment results is that a majority of mismatches came from the old code timing out whilst the new code succeeded in time. This is great news — it means we’re solving a real performance issue with user facing effect, not only making a graph look prettier.
After ignoring all experiments where the control was timing out, the remaining mismatches were caused by differing timestamps in the generated commits: our new RPC API was missing a “time” argument (the time at which the merge commit was created), and was using the local time in the fileserver instead. Since the experiment is perfomed sequentially, it was very easy to end up with mismatched timestamps between the control and the candidate, particularly for merges that take more than 1s. We fixed this by adding an explicit time argument to the RPC call, and after deploying, all the trivial mismatches were gone from the graph.
Once we had some basic level of trust in the new implementation, it was time to increase the percentage of requests for which the experiment runs. More requests leads to more accurate performance stats and more corner cases where the new implementation was giving incorrect results.
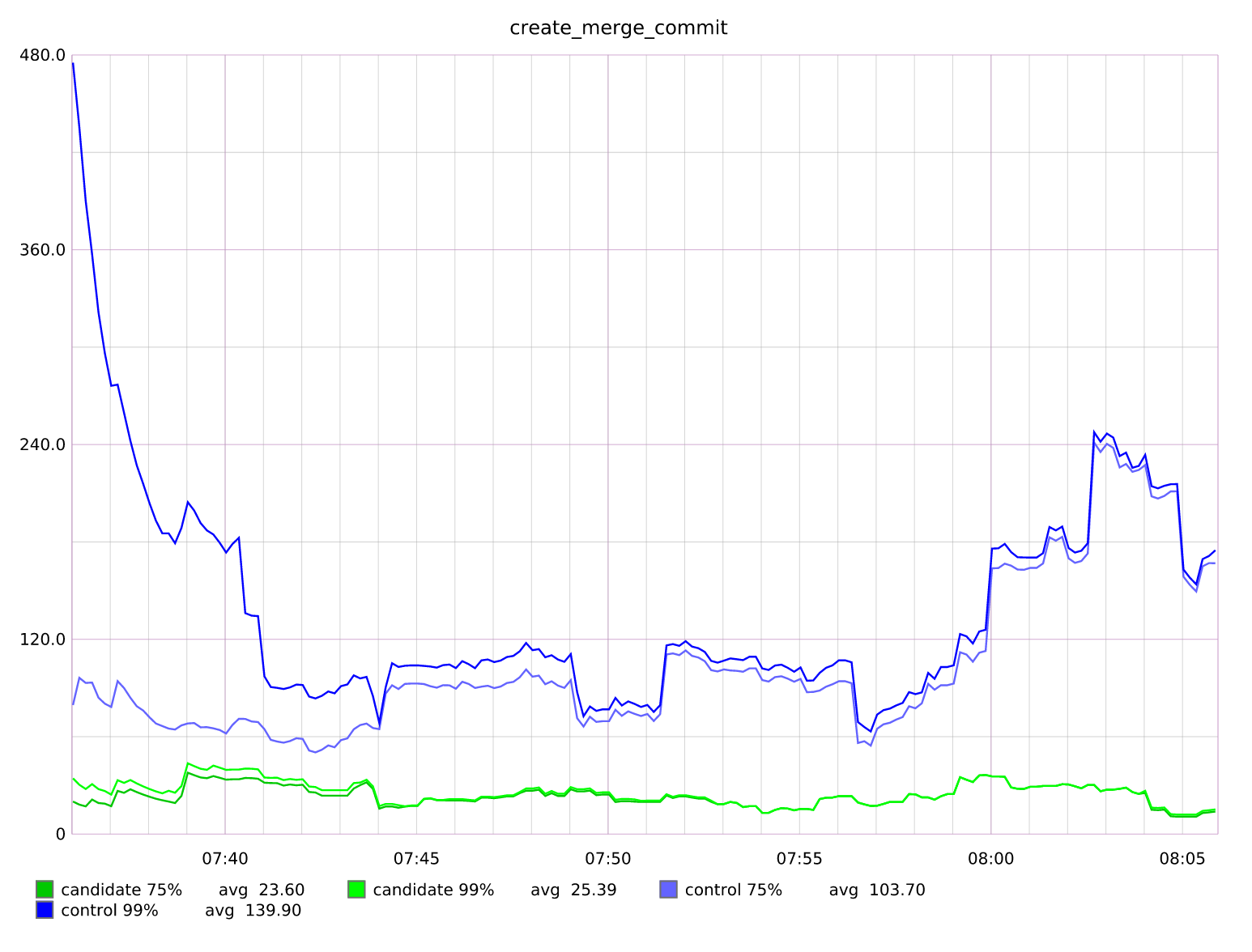
Simply looking at the performance graph makes it obvious that, even though for the average case the new code is significantly faster than the old implementation, there are performance spikes that need to be handled.
Finding the cause of these spikes is trivial thanks to our tooling: we can configure Scientist to log any experiments where the candidate takes longer than Xms to run (in our case we aimed at 5000ms), and let it run overnight capturing this data.
We did that for 4 days, every morning waking up to a tidy list of cases where the result of the new code was different from the old code, and cases where the new code was just giving good results but running too slowly.
Consequently, our workflow is straightforward: we fix the mismatches and the performance issues, we deploy again to production, and we continue running the experiments, until there are no mismatches and no slow runs. It is worth noting that we fix both performance problems and mismatches with no priority for either: the old adage of “make it work and then make it fast” is pointless here — and in all of GitHub’s systems. If it’s not fast, it is not working, at least not properly.
As a sample, here are a few of the cases we fixed over these 4 days:
- Performance wise, we noticed a lot of merges that were “conflicts” (i.e. they could not be merged by either Git or libgit2), and yet libgit2 was taking a huge amount of time to declare the merge a conflict: 3ms for Git vs more than 8s in libgit2.Tracing the execution of the two code paths we noticed the reason why Git was so fast: our Git shell script was exiting as soon as it found a conflict, whereas libgit2 would continue resolving the merge until it had the resulting full index with conflicts in it. We have no use for an index with conflicts on it, so the solution to this performance issue was simple: adding a flag to make libgit2 abort the merge as soon as it finds any conflicts.
- We also found a serious O(n) algorithm issue in libgit2: the code to write the REUC (an extension on the index that contains extra information — usually for Git GUIs) was taking too long to run in large repositories.There is no use for the REUC in our implementation, because we discard the index directly after having written the tree and commit, so we fixed the issue by adding a flag to libgit2 that skips writing the REUC altogether. While we were in the codebase, however, we fixed the O(n) issue in the REUC and made it run hundreds of times faster!
- The first issue we found that was a mismatch in the results instead of a performance problem was a series of merges that Git was completing succesfully but libgit2 was marking as conflicts.All the mismatched merges had the same case: the ancestor had a file with a given filemode, whilst one side of the merge had removed the file and the other side had changed the filemode.This kind of situation should be marked as a conflict, but Git was erroneously resolving the merge and removing the file from the merge result (ignoring the fact that one side of the merge had changed the filemode of the same file).When comparing the code in libgit2 and Git for these operations, we noticed that the old merge strategy in Git was simply not handling the case properly and libgit2 was. So we fixed the bug upstream in Git and moved on.
- A much more interesting case happened when a merge that was clearly a conflict in libgit2 was being merged successfuly by Git. After some debugging, we found that the merge that Git was generating was broken — the single file that was being merged was definitely not a valid merge, and it even included conflict markers in the output!It took a bit more digging to find out the reason why Git was “successfully” merging this file. We noticed that the file in question happened to have exactly 768 conflicts between the old and the new version. This is a very peculiar number. The man page for
git-merge-one-fileconfirmed our
suspicions:The exit value of this program is negative on error, and the number of
conflicts otherwise. If the merge was clean, the exit value is 0.Given that shells only use the lowest 8 bits of a program’s exit code, it’s obvious why Git could merge this file: the 768 conflicts were being reported as 0 by the shell, because 768 is a multiple of 256!
This bug was intense. But one more time, libgit2 was doing the right thing, so again we fixed the issue upstream in Git and continued with the experiments.
- The last interesting case was a merge that was apparently trivial to Git and sparking thousands of conflicts under libgit2. It took us a while to notice that the reason libgit2 couldn’t merge was because it was picking the wrong merge base.Tracing the execution of libgit2 and Git in parallel, we noticed that libgit2 was missing a whole step in the merge base calculation algorithm: redundant merge base simplification. After implementing the extra step of the algorithm, libgit2 was resolving the same merge base as Git and the final merge was identical.We finally found a bug in libgit2, although in this case more than a bug it was a whole feature which we forgot to implement!
Conclusion
After 4 days of iterating on this process, we managed to get the experiment running for 100% of the requests, for 24 hours, and with no mismatches nor slow cases during the whole run. In total, Scientist verified tens of millions of merge commits to be virtually identical in the old and new paths. Our experiment was a success.
The last thing to do was the most exciting one: remove the Scientist code and switch all the frontend machines to run the new code by default. In a matter of hours, the new code was deployed and running for 100% of the production traffic in GitHub. Finally, we removed the old implementation — which frankly is the most gratifying part of this whole process.
To sum it up: In roughly 5 days of part-time work, we’ve replaced one of GitHub’s more critical code paths with no user-visible effects. As part of this process, we’ve fixed 2 serious merge-related bugs in the original Git implementation which had gone undetected for years, and 3 major performance issues in the new implementation. The 99th percentile of the new implementation is roughly equivalent to the 95th of the old implementation.
This kind of aggressive technical debt cleanup and optimization work can only happen as a by-product of our engineering ecosystem. Without being able to deploy the main application more than 60 times in a day, and without the tooling to automatically test and benchmark two wildly different implementations in production, this process would have taken months of work and there would be no realistic way to ensure that there were no performance or behavior regressions.
Written by

Related posts

How GitHub engineers tackle platform problems
Our best practices for quickly identifying, resolving, and preventing issues at scale.
GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it
Plus, considerations in updating one of GitHub’s oldest and most heavily used features.

Design system annotations, part 2: Advanced methods of annotating components
How to build custom annotations for your design system components or use Figma’s Code Connect to help capture important accessibility details before development.