GLB: GitHub’s open source load balancer
At GitHub, we serve tens of thousands of requests every second out of our network edge, operating on GitHub’s metal cloud. We’ve previously introduced GLB, our scalable load balancing solution…
At GitHub, we serve tens of thousands of requests every second out of our network edge, operating on GitHub’s metal cloud. We’ve previously introduced GLB, our scalable load balancing solution for bare metal datacenters, which powers the majority of GitHub’s public web and git traffic, as well as fronting some of our most critical internal systems such as highly available MySQL clusters. Today we’re excited to share more details about our load balancer’s design, as well as release the GLB Director as open source.
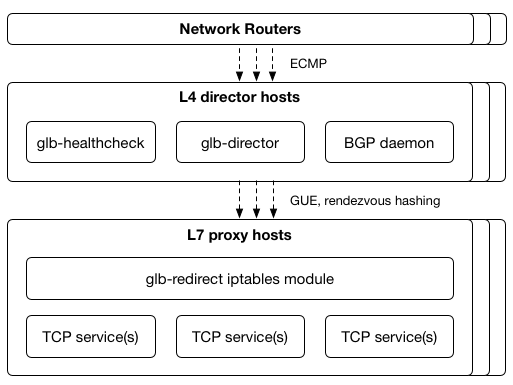
GLB Director is a Layer 4 load balancer which scales a single IP address across a large number of physical machines while attempting to minimise connection disruption during any change in servers. GLB Director does not replace services like haproxy and nginx, but rather is a layer in front of these services (or any TCP service) that allows them to scale across multiple physical machines without requiring each machine to have unique IP addresses.
Scaling an IP using ECMP
The basic property of a Layer 4 load balancer is the ability to take a single IP address and spread inbound connections across multiple servers. To scale a single IP address to handle more traffic than any single machine can process, we need to not only split amongst backend servers, but also need to be able to scale up the servers that handle the load balancing themselves. This is essentially another layer of load balancing.
Typically we think of an IP address as referencing a single physical machine, and routers as moving a packet to the next closest router to that machine. In the simplest case where there’s always a single best next hop, routers pick that hop and forward all packets there until the destination is reached.

In reality, most networks are far more complicated. There is often more than a single path available between two machines, for example where multiple ISPs are available or even when two routers are joined together with more than one physical cable to increase capacity and provide redundancy. This is where Equal-Cost Multi-Path (ECMP) routing comes in to play – rather than routers picking a single best next hop, where they have multiple hops with the same cost (usually defined as the number of ASes to the destination), they instead hash traffic so that connections are balanced across all available paths of equal cost.
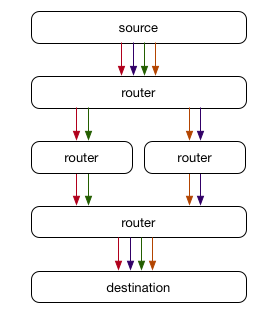
ECMP is implemented by hashing each packet to determine a relatively consistent selection of one of the available paths. The hash function used here varies by device, but typically it’s a consistent hash based on the source and destination IP address as well as the source and destination port for TCP traffic. This means that multiple packets for the same ongoing TCP connection will typically traverse the same path, meaning that packets will arrive in the same order even when paths have different latencies. Notably in this case, the paths can change without any disruption to connections because they will always end up at the same destination server, and at that point the path it took is mostly irrelevant.
An alternative use of ECMP can come in to play when we want to shard traffic across multiple servers rather than to the same server over multiple paths. Each server can announce the same IP address with BGP or another similar network protocol, causing connections to be sharded across those servers, with the routers blissfully unaware that the connections are being handled in different places, not all ending on the same machine as would traditionally be the case.
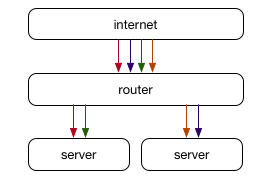
While this shards traffic as we had hoped, it has one huge drawback: when the set of servers that are announcing the same IP change (or any path or router along the way changes), connections must rebalance to maintain an equal balance of connections on each server. Routers are typically stateless devices, simply making the best decision for each packet without consideration to the connection it is a part of, which means some connections will break in this scenario.
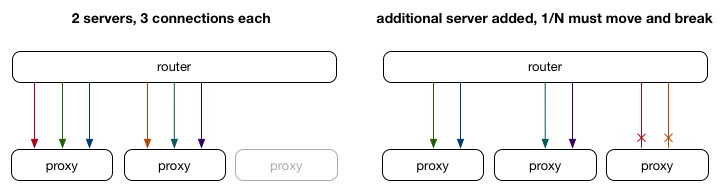
In the above example on the left, we can imagine that each colour represents an active connection. A new proxy server is added to announce the same IP. The router diligently adjusts the consistent hash to move 1/3 connections to the new server while keeping 2/3 connections where they were. Unfortunately for those 1/3 connections that were already in progress, the packets are now arriving on a server that doesn’t know about the connection, and so they fail.
Split director/proxy load balancer design
The issue with the previous ECMP-only solution is that it isn’t aware of the full context for a given packet, nor is it able to store data for each packet/connection. As it turns out, there are commonly used patterns to help out with this situation by implementing some stateful tracking in software, typically using a tool like Linux Virtual Server (LVS). We create a new tier of “director” servers that take packets from the router via ECMP, but rather than relying on the router’s ECMP hashing to choose the backend proxy server, we instead control the hashing and store state (which backend was chosen) for all in-progress connections. When we change the set of proxy tier servers, the director tier hopefully hasn’t changed, and our connection will continue.
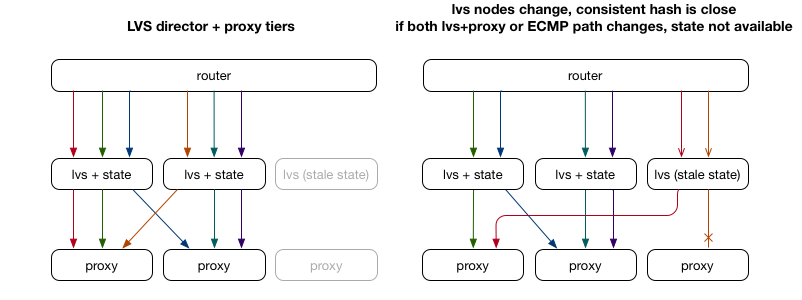
Although this works well in many cases, it does have some drawbacks. In the above example, we add both a LVS director and backend proxy server at the same time. The new director receives some set of packets, but doesn’t have any state yet (or has delayed state), so hashes it as a new connection and may get it wrong (and cause the connection to fail). A typical workaround with LVS is to use multicast connection syncing to keep the connection state shared amongst all LVS director servers. This still requires connection state to propagate, and also still requires duplicate state – not only does each proxy need state for each connection in the Linux kernel network stack, but every LVS director also needs to store a mapping of connection to backend proxy server.
Removing all state from the director tier
When we were designing GLB, we decided we wanted to improve on this situation and not duplicate state at all. GLB takes a different approach to that described above, by using the flow state already stored in the proxy servers as part of maintaining established Linux TCP connections from clients.
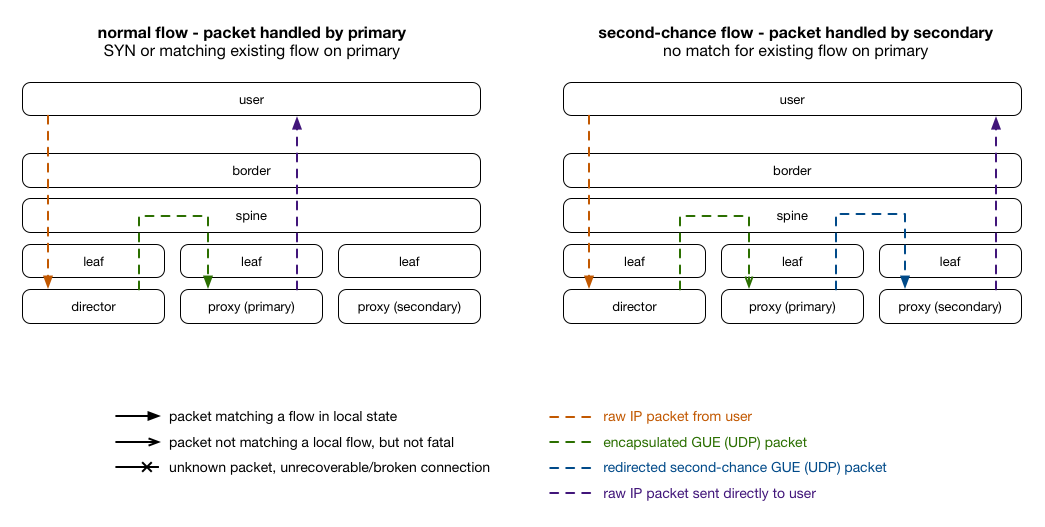
For each incoming connection, we pick a primary and secondary server that could handle that connection. When a packet arrives on the primary server and isn’t valid, it is forwarded to the secondary server. The hashing to choose the primary/secondary server is done once, up front, and is stored in a lookup table, and so doesn’t need to be recalculated on a per-flow or per-packet basis. When a new proxy server is added, for 1/N connections it becomes the new primary, and the old primary becomes the secondary. This allows existing flows to complete, because the proxy server can make the decisions with its local state, the single source of truth. Essentially this gives packets a “second chance” at arriving at the expected server that holds their state.
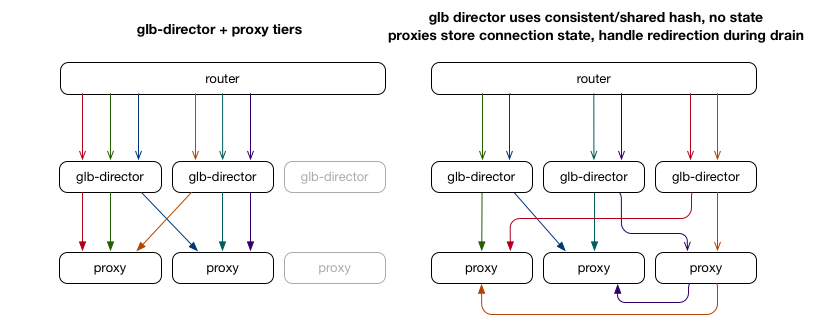
Even though the director will still send connections to the wrong server, that server will then know how to forward on the packet to the correct server. The GLB director tier is completely stateless in terms of TCP flows: director servers can come and go at any time, and will always pick the same primary/secondary server providing their forwarding tables match (but they rarely change). To change proxies, some care needs to be taken, which we describe below.
Maintaining invariants: rendezvous hashing
The core of the GLB Director design comes down to picking that primary and secondary server consistently, and to allow the proxy tier servers to drain and fill as needed. We consider each proxy server to have a state, and carefully adjust the state as a way of adding and removing servers.
We create a static binary forwarding table, which is generated identically on each director server, to map incoming flows to a given primary and secondary server. Rather than having complex logic to pick from all available servers at packet processing time, we instead use some indirection by creating a table (65k rows), with each row containing a primary and secondary server IP address. This is stored in memory as flat array of binary data, taking about 512kb per table. When a packet arrives, we consistently hash it (based on packet data alone) to the same row in that table (using the hash as an index into the array), which provides a consistent primary and secondary server pair.
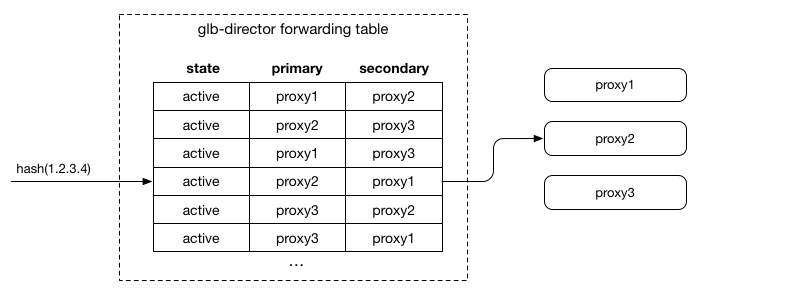
We want each server to appear approximately equally in both the primary and secondary fields, and to never appear in both in the same row. When we add a new server, we desire some rows to have their primary become secondary, and the new server become primary. Similarly, we desire the new server to become secondary in some rows. When we remove a server, in any rows where it was primary, we want the secondary to become primary, and another server to pick up secondary.
This sounds complex, but can be summarised succinctly with a couple of invariants:
- As we change the set of servers, the relative order of existing servers should be maintained.
- The order of servers should be computable without any state other than the list of servers (and maybe some predefined seeds).
- Each server should appear at most once in each row.
- Each server should appear approximately an equal number of times in each column.
Reading the problem that way, Rendezvous hashing is an ideal choice, since it can trivially satisfy these invariants. Each server (in our case, the IP) is hashed along with the row number, the servers are sorted by that hash (which is just a number), and we get a unique order for servers for that given row. We take the first two as the primary and secondary respectively.
Relative order will be maintained because the hash for each server will be the same regardless of which other servers are included. The only information required to generate the table is the IPs of the servers. Since we’re just sorting a set of servers, the servers only appear once. Finally, if we use a good hash function that is pseudo-random, the ordering will be pseudo-random, and so the distribution will be even as we expect.
Draining, filling, adding and removing proxies
Adding or removing proxy servers require some care in our design. This is because a forwarding table entry only defines a primary/secondary proxy, so the draining/failover only works with at most a single proxy host in draining. We define the following valid states and state transitions for a proxy server:
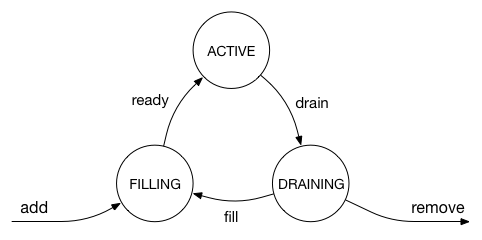
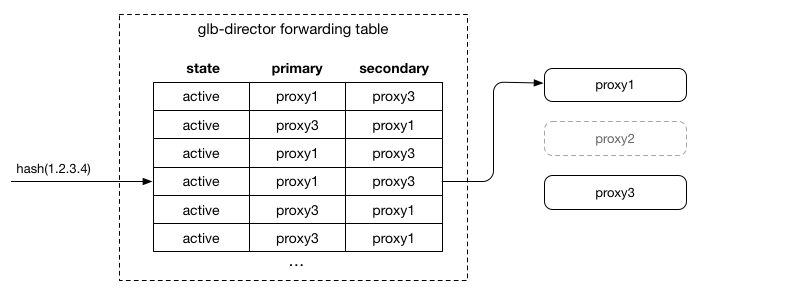
When a proxy server is active, draining or filling, it is included in the forwarding table entries. In a stable state, all proxy servers are active, and the rendezvous hashing described above will have an approximately even and random distribution of each proxy server in both the primary and secondary columns.
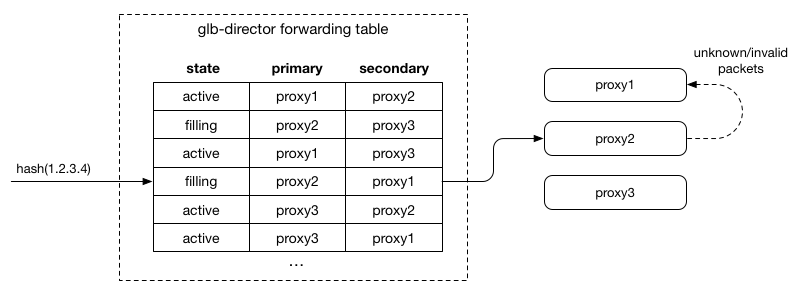
As a proxy server transitions to draining, we adjust the entries in the forwarding table by swapping the primary and secondary entries we would have otherwise included:
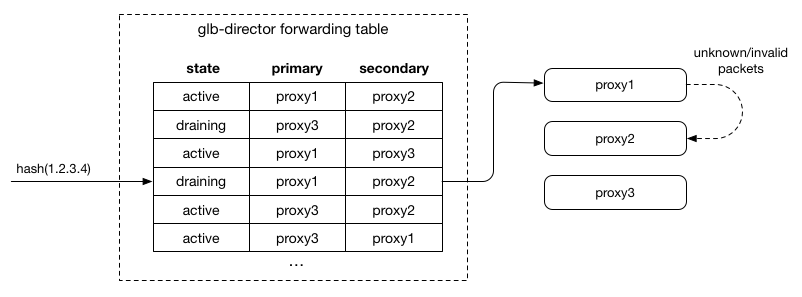
This has the effect of sending packets to the server that was previously secondary first. Since it receives the packets first, it will accept SYN packets and therefore take any new connections. For any packet it doesn’t understand as relating to a local flow, it forwards it to the other server (the previous primary), which allows existing connections to complete.
This has the effect of draining the desired server of connections gracefully, after which point it can be removed completely, and proxies can shuffle in to fill the empty secondary slots:
A node in filling looks just like active, since the table inherently allows a second chance:
This implementation requires that no more than one proxy server at a time is in any state other than active, which in practise has worked well at GitHub. The state changes to proxy servers can happen as quickly as the longest connection duration that needs to be maintained. We’re working on extensions to the design that support more than just a primary and secondary, and some components (like the header listed below) already include initial support for arbitrary server lists.
Encapsulation within the datacenter
We now have an algorithm to consistently pick backend proxy servers and operate on them, but how do we actually move packets around the datacenter? How do we encode the secondary server inside the packet so the primary can forward a packet it doesn’t understand?
Traditionally in the LVS setup, an IP over IP (IPIP) tunnel is used. The client IP packet is encapsulated inside an internal datacenter IP packet and forwarded on to the proxy server, which decapsulates it. We found that it was difficult to encode the additional server metadata inside IPIP packets, as the only standard space available was the IP Options, and our datacenter routers passed packets with unknown IP options to software for processing (which they called “Layer 2 slow path”), taking speeds from millions to thousands of packets per second.
To avoid this, we needed to hide the data inside a different packet format that the router wouldn’t try to understand. We initially adopted raw Foo-over-UDP (FOU) with a custom Generic Route Encapsulation (GRE) payload, essentially encapsulating everything inside a UDP packet. We recently transitioned to Generic UDP Encapsulation (GUE), which is a layer on top FOU which provides a standard for encapsulating IP protocols inside a UDP packet. We place our secondary server’s IP inside the private data of the GUE header. From a router’s perspective, these packets are all internal datacenter UDP packets between two normal servers.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source port | Destination port | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ UDP
| Length | Checksum | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+/
| 0 |C| Hlen | Proto/ctype | Flags | GUE
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Private data type (0) | Next hop idx | Hop count |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |
| Hop 0 | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ GLB
| ... | private
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ data
| Hop N | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+/Another benefit to using UDP is that the source port can be filled in with a per-connection hash so that they are flow within the datacenter over different paths (where ECMP is used within the datacenter), and received on different RX queues on the proxy server’s NIC (which similarly use a hash of TCP/IP header fields). This is not possible with IPIP because most commodity datacenter NICs are only able to understand plain IP, TCP/IP and UDP/IP (and a few others). Notably, the NICs we use cannot look inside IP/IP packets.
When the proxy server wants to send a packet back to the client, it doesn’t need to be encapsulated or travel back through our director tier, it can be sent directly to the client (often called “Direct Server Return”). This is typical of this sort of load balancer design and is especially useful for content providers where the majority of traffic flows outbound with a relatively small amount of traffic inbound.
This leaves us with a packet flow that looks like the following:
DPDK for 10G+ line rate packet processing
Since we first publicly discussed our initial design, we’ve completely rewritten glb-director to use DPDK, an open source project that allows very fast packet processing from userland by bypassing the Linux kernel. This has allowed us to achieve NIC line rate processing on commodity NICs with commodity CPUs, and allows us to trivially scale our director tier to handle as much inbound traffic as our public connectivity requires. This is particularly important during DDoS attacks, where we do not want our load balancer to be a bottleneck.
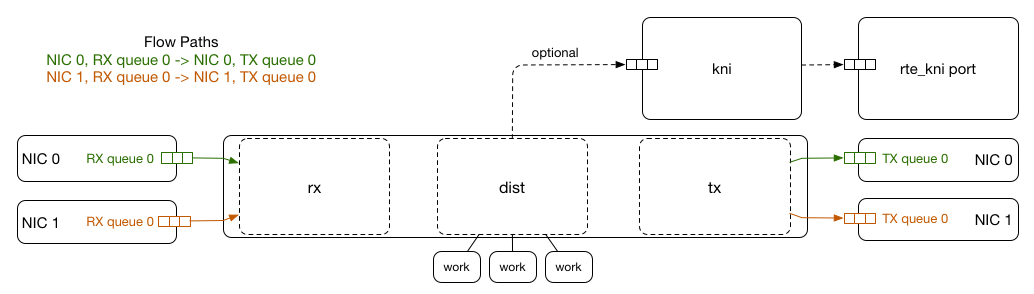
One of our initial goals with GLB was that our load balancer could run on commodity datacenter hardware without any server-specific physical configuration. Both GLB director and proxy servers are provisioned like normal servers in our datacenter. Each server has a bonded pair of network interfaces, and those interfaces are shared between DPDK and Linux on GLB director servers.
Modern NICs support SR-IOV, a technology that enables a single NIC to act like multiple NICs from the perspective of the operating system. This is typically used by virtual machine hypervisors to ask the real NIC (“Physical Function”) to create multiple pretend NICs for each VM (“Virtual Functions”). To enable DPDK and the Linux kernel to share NICs, we use flow bifurcation, which sends specific traffic (destined to GLB-run IP addresses) to our DPDK process on a Virtual Function while leaving the rest of the packets with the Linux kernel’s networking stack on the Physical Function.
We’ve found that the packet processing rates of DPDK on a Virtual Function are acceptable for our requirements. GLB Director uses a DPDK Packet Distributor pattern to spread the work of encapsulating packets across any number of CPU cores on the machine, and since it is stateless this can be highly parallelised.
GLB Director supports matching and forwarding inbound IPv4 and IPv6 packets containing TCP payloads, as well as inbound ICMP Fragmentation Required messages used as part of Path MTU Discovery, by peeking into the inner layers of the packet during matching.
Bringing test suites to DPDK with Scapy
One problem that typically arises in creating (or using) technologies that operate at high speeds due to using low-level primitives (like communicating with the NIC directly) is that they become significantly more difficult to test. As part of creating the GLB Director, we also created a test environment that supports simple end-to-end packet flow testing of our DPDK application, by leveraging the way DPDK provides an Environment Abstraction Layer (EAL) that allows a physical NIC and a libpcap-based local interface to appear the same from the view of the application.
This allowed us to write tests in Scapy, a wonderfully simple Python library for reading, manipulating and writing packet data. By creating a Linux Virtual Ethernet Device, with Scapy on one side and DPDK on the other, we were able to pass in custom crafted packets and validate what our software would provide on the other side, being a fully GUE-encapsulated packet directed to the expected backend proxy server.
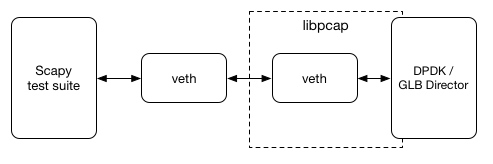
This allows us to test more complex behaviours such as traversing layers of ICMPv4/ICMPv6 headers to retrieve the original IPs and TCP ports for correct forwarding of ICMP messages from external routers.
Healthchecking of proxies for auto-failover
Part of the design of GLB is to handle server failure gracefully. The current design of having a designated primary/secondary for a given forwarding table entry / client means that we can work around single-server failure by running health checks from the perspective of each director. We run a service called glb-healthcheck which continually validates each backend server’s GUE tunnel and arbitrary HTTP port.
When a server fails, we swap the primary/secondary entries anywhere that server is primary. This performs a “soft drain” of the server, which provides the best chance for connections to gracefully fail over. If the healthcheck failure is a false positive, connections won’t be disrupted, they will just traverse a slightly different path.
Second chance on proxies with iptables
The final component that makes up GLB is a Netfilter module and iptables target that runs on every proxy server and allows the “second chance” design to function.
This module provides a simple task deciding whether the inner TCP/IP packet inside every GUE packet is valid locally according to the Linux kernel TCP stack, and if it isn’t, forwards it to the next proxy server (the secondary) rather than decapsulating it locally.
In the case where a packet is a SYN (new connection) or is valid locally for an established connection, it simply accepts it locally. We then use the Linux kernel 4.x GUE support provided as part of the fou module to receive the GUE packet and process it locally.
Available today as open source
When we started down the path of writing a better datacenter load balancer, we decided that we wanted to release it open source so that others could benefit from and share in our work. We’re excited to be releasing all the components discussed here as open source at github/glb-director. We hope this will allow others to reuse our work and contribute to a common standard software load balancing solution that runs on commodity hardware in physical datacenter environments.
Also, we’re hiring!
GLB and the GLB Director has been an ongoing project designed, authored, reviewed and supported by various members of GitHub’s Production Engineering organisation, including @joewilliams, @nautalice, @ross, @theojulienne and many others. If you’re interested in joining us in building great infrastructure projects like GLB, our Data Center team is hiring production engineers specialising in Traffic Systems, Network and Facilities.
Written by

Related posts

How GitHub engineers tackle platform problems
Our best practices for quickly identifying, resolving, and preventing issues at scale.
GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it
Plus, considerations in updating one of GitHub’s oldest and most heavily used features.

Design system annotations, part 2: Advanced methods of annotating components
How to build custom annotations for your design system components or use Figma’s Code Connect to help capture important accessibility details before development.