Introducing the new GitHub Status Site
Performance and reliability conversations as a GitHub product

Developers and teams expect business-critical services to be reliable. From our perspective, reliability can be defined by three questions: is the product available, how well does the product recover from failure, and how performant is the product as it evolves over time. In order for millions of developers to develop, build, and deploy their software, the underlying platform that powers GitHub must be resilient to a wide range of failure modes. We understand that our products need to satisfy the levels of trust our community expects of us when putting their code and their livelihoods on our platform. Today, we are pleased to announce the new GitHub Status Page.
Behind the Scenes
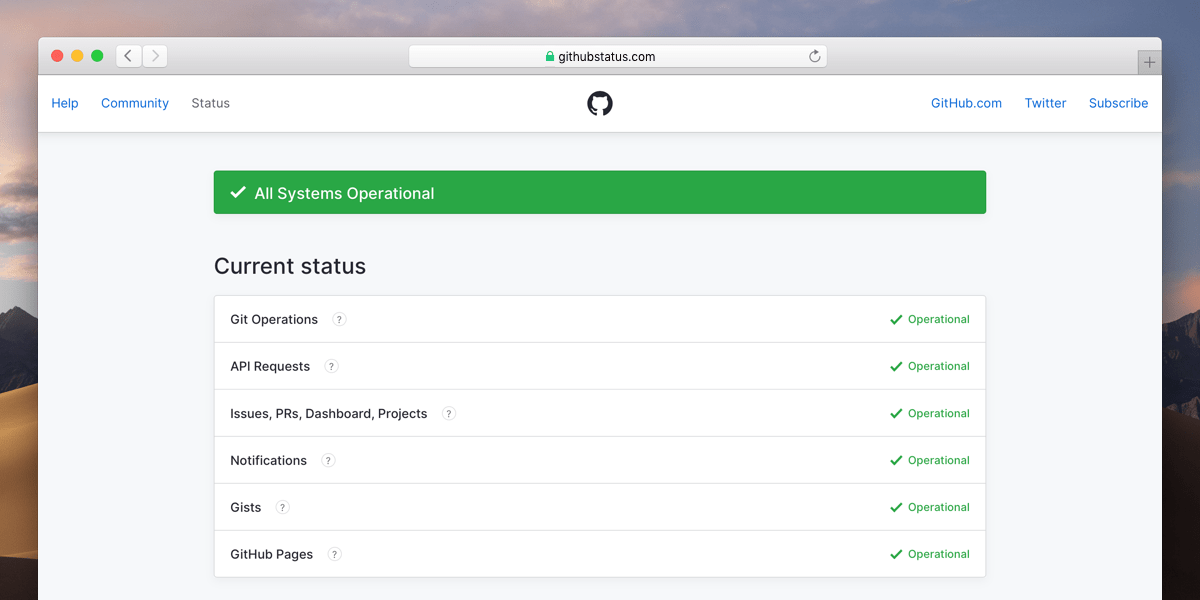
GitHub is built on a platform of distributed services, spread over multiple data centers across the globe. An incident can occur on any of one these platform tiers, affecting either a standalone service or a cluster of interrelated components. With that in mind, we needed a way to accurately communicate this level of granularity to our users and designed a new status page to provide this functionality.
Our new status site now lists the individual component statuses that make up our wider product. Now GitHub can communicate the statuses of components that matter most to our users, and users can subscribe to them. Git operations, for example, are now split out from API requests, and Pages builds can be tracked independently of Notifications. This makes our messaging during an incident more accurate and reliable.
In addition to splitting out the component products on the status site, we’ve also focused on improving and organizing the information we provide to users during an incident. Our goal has been to change our workflow to improve our customer communication during an incident and to reduce friction for incident commanders.
To do this, we started by decoupling the idea of a component status update (e.g. Pages is experiencing degraded performance) from the lifecycle of an incident. The degraded performance of a component could be representative of a wider incident, but updating its status does not allow us to track and share mitigation steps and descriptive updates. In other words, status updates are snapshots in time of a specific component, and incidents are trackable communications between GitHub and customers.
Integrating the new status into your operations
One of the benefits of the new status site is the ability to subscribe to our status changes in multiple ways, such as email, SMS, or webhook delivery. These subscriptions can follow the entire lifecycle of an incident from investigation to remediation. For example, if you’re using Jenkins to run a Continuous Delivery pipeline and our Git operations experience a service slowdown, you could create a webhook to have your Jenkins system apply a backoff mechanism to prevent downstream errors.
Deprecating the old status site
Over the next three months, we’ll continue to support our old status site, as well as its API. So you’ll have time to move any integrations over to the new site. Throughout February leading up to the deprecation, we will perform brownouts in an effort to help you identify systems that may be pointing at the deprecated site. At the end of February, we’ll be adding a redirect for web traffic to the new status page and fully shutting down the old API.
Testing out the new site
In addition to deprecating the old site, we will test the new one on our live systems. On December 18, 2018, we’ll be running a test of our new incident response workflow at 10:00 PST (18:00 UTC). Throughout this test, we will have an active incident that starts with "TEST". This test will not reflect the real status of our products, but will only serve as a way to test new tooling, processes, and the status site. Our component products will not be going through any disaster recovery processes. You will notice during that time that services may appear to be degraded via the status site but that won’t be the case. If you do find any issues or problems with the status site during this time, please reach out to us.
Reliability as a product feature
The new status site is the first of many public commitments we’ve made at GitHub to treat reliability and performance as a product feature. Doing so is a responsibility, not only of the engineers, but of our entire organization. This means that product managers and designers care about and prioritize reliability along with and against new features. Over the coming months, we’ll continue to build on this theme, so you can keep putting your trust and your software development workflows on GitHub.
Have feedback? Let us know what you think of the new status page.
Written by

Related posts

How GitHub engineers tackle platform problems
Our best practices for quickly identifying, resolving, and preventing issues at scale.
GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it
Plus, considerations in updating one of GitHub’s oldest and most heavily used features.

Design system annotations, part 2: Advanced methods of annotating components
How to build custom annotations for your design system components or use Figma’s Code Connect to help capture important accessibility details before development.