Harness the power of CodeQL. Get started now.
Fixing security vulnerabilities with AI
A peek under the hood of GitHub Advanced Security code scanning autofix.

|
|
11 minutes
Copilot Autofix is now generally available.
In November 2023, we announced the launch of code scanning autofix, leveraging AI to suggest fixes for security vulnerabilities in users’ codebases. This post describes how autofix works under the hood, as well as the evaluation framework we use for testing and iteration.
What is code scanning autofix?
GitHub code scanning analyzes the code in a repository to find security vulnerabilities and other errors. Scans can be triggered on a schedule or upon specified events, such as pushing to a branch or opening a pull request. When a problem is identified, an alert is presented to the user. Code scanning can be used with first- or third-party alerting tools, including open source and private tools. GitHub provides a first party alerting tool powered by CodeQL, our semantic code analysis engine, which allows querying of a codebase as though it were data. Our in-house security experts have developed a rich set of queries to detect security vulnerabilities across a host of popular languages and frameworks. Building on top of this detection capability, code scanning autofix takes security a step further, by suggesting AI-generated fixes for alerts. In its first iteration, autofix is enabled for CodeQL alerts detected in a pull request, beginning with JavaScript and TypeScript alerts. It explains the problem and its fix strategy in natural language, displays the suggested fix directly in the pull request page, and allows the developer to commit, dismiss, or edit the suggestion.
The basic idea behind autofix is simple: when a code analysis tool such as CodeQL detects a problem, we send the affected code and a description of the problem to a large language model (LLM), asking it to suggest code edits that will fix the problem without changing the functionality of the code. The following sections delve into some of the details and subtleties of constructing the LLM prompt, processing the model’s response, evaluating the quality of the feature, and serving it to our users.
The autofix prompt
At the core of our technology lies a request to an LLM, expressed through an LLM prompt. CodeQL static analysis detects a vulnerability, generating an alert that references the problematic code location as well as any other relevant locations. For example, for a SQL-injection vulnerability, the alert flags the location where tainted data is used to build a database query, and also includes one or more flow paths showing how untrusted data may reach this location without sanitization. We extract information from the alert to construct an LLM prompt consisting of:
- General information about this type of vulnerability, typically including a general example of the vulnerability and how to fix it, extracted from the CodeQL query help.
- The source-code location and content of the alert message.
- Relevant code snippets from the locations all along the flow path and any code locations referenced in the alert message.
- Specification of the response we expect.
We then ask the model to show us how to edit the code to fix the vulnerability.
We describe a strict format for the model output, to allow for automated processing. The model outputs Markdown consisting of the following sections:
- Detailed natural language instructions for fixing the vulnerability.
- A full specification of the needed code edits, following the format defined in the prompt.
- A list of dependencies that should be added to the project, if applicable. This is needed, for example, if the fix makes use of a third-party sanitization library on which the project does not already depend.
We surface the natural language explanation to users together with the code scanning alert, followed by a diff patch constructed from the code edits and added dependencies. Users can review the suggested fix, edit and adjust it if necessary, and apply it as a commit in their pull request.
Pre- and post-processing
If our goal were to produce a nice demo, this simple setup would suffice. Supporting real-world complexity and overcoming LLM limitations, however, requires a combination of careful prompt crafting and post-processing heuristics. A full description of our approach is beyond the scope of this post, but we outline some of the more impactful aspects below.
Selecting code to show the model
CodeQL alerts include location information for the alert and sometimes steps along the data flow path from the source to the sink. Sometimes additional source-code locations are referenced in the alert message. Any of these locations may require edits to fix the vulnerability. Further parts of the codebase, such as the test suite, may also need edits, but we focus on the most likely candidates due to prompt length constraints.
For each of these code locations, we use a set of heuristics to select a surrounding region that provides the needed context while minimizing lines of code, eliding less relevant parts as needed to achieve the target length. The region is designed to include the imports and definitions at the top of the file, as these often need to be augmented in the fix suggestion. When multiple locations from the CodeQL alert reside in the same file, we structure a combined code snippet that gives the needed context for all of them.
The result is a set of one or more code snippets, potentially from multiple source-code files, showing the model the parts of the project where edits are most likely to be needed, with line numbers added so as to allow reference to specific lines both in the model prompt and in the model response. To prevent fabrications, we explicitly constrain the model to make edits only to the code included in the prompt.
Adding dependencies
Some fixes require adding a new project dependency, such as a data sanitation library. To do so, we need to find the configuration file(s) that list project dependencies, determine whether the needed packages are already included, and if not make the needed additions. We could use an LLM for all these steps, but this would require showing the LLM the list of files in the codebase as well as the contents of the relevant ones. This would increase both the number of model calls and the number of prompt tokens. Instead, we simply ask the model to list external dependencies used in its fix. We implement language-specific heuristics to locate the relevant configuration file, parse it to determine whether the needed dependencies already exist, and if not add the needed edits to the diff patch we produce.
Specifying a format for code edits
We need a compact format for the model to specify code edits. The most obvious choice would be asking the model to output a standard diff patch directly. Unfortunately, experimentation shows that this approach exacerbates the model’s known difficulties with arithmetic, often yielding incorrect line number computations without enough code context to make heuristic corrections. We experimented with several alternatives, including defining a fixed set of line edit commands the model can use. The approach that yielded the best results in practice involves allowing the model to provide “before” and “after” code blocks, demonstrating the snippets that require changes (including some surrounding context lines) and the edits to be made.
Overcoming model errors
We employ a variety of post-processing heuristics to detect and correct small errors in the model output. For example, “before” code blocks might not exactly match the original source-code, and line numbers may be slightly off. We implement a fuzzy search to match the original code, overcoming and correcting errors in indentation, semicolons, code comments, and the like. We use a parser to check for syntax errors in the edited code. We also implement semantic checks such as name-resolution checks and type checks. If we detect errors we are unable to fix heuristically, we flag the suggested edit as (partially) incorrect. In cases where the model suggests new dependencies to add to the project, we verify that these packages exist in the ecosystem’s package registry and check for known security vulnerabilities or malicious packages.
Evaluation and iteration
To make iterative improvements to our prompts and heuristics while at the same time minimizing LLM compute costs, we need to evaluate fix suggestions at scale. In taking autofix from demo quality to production quality, we relied on an extensive automated test harness to enable fast evaluation and iteration.
The first component of the test harness is a data collection pipeline that processes open source repositories with code scanning alerts, collecting alerts that have test coverage for the alert location. For JavaScript / TypeScript, the first supported languages, we collected over 1,400 alerts with test coverage from 63 CodeQL queries.
The second component of the test harness is a GitHub Actions workflow that runs autofix on each alert in the evaluation set. After committing the generated fix in a fork, the workflow runs both CodeQL and the repository’s test suite to evaluate the validity of the fix. In particular, a fix is considered successful only if:
- It removes the CodeQL alert.
- It introduces no new CodeQL alerts.
- It produces no syntax errors.
- It does not change the outcome of any of the repository tests.
As we iterated on the prompt, the code edit format, and various post-processing heuristics, we made use of this test harness to ensure that our changes were improving our success rate. We coupled the automated evaluations with periodic manual triage, to focus our efforts on the most prevalent problems, as well as to validate the accuracy of the automated framework. This rigorous approach to data-driven development allowed us to triple our success rate while at the same time reducing LLM compute requirements by a factor of six.
Architecture, infrastructure, and user experience
Generating useful fixes is a first step, but surfacing them to our users requires further front- and back-end modifications. Designing for simplicity, we’ve built autofix on top of existing functionality wherever possible. The user experience enhances the code scanning pull request experience. Along with a code scanning alert, users can now see a suggested fix, which may include suggested changes in multiple files, optionally outside the scope of the pull request diff. A natural language explanation of the fix is also displayed. Users can commit the suggested fixes directly to the pull request, or edit the suggestions in their local IDE or in a GitHub Codespace.
The backend, too, is built on top of existing code scanning infrastructure, making it seamless for our users. Customers do not need to make any changes to their code scanning workflows to see fix suggestions for supported CodeQL queries.
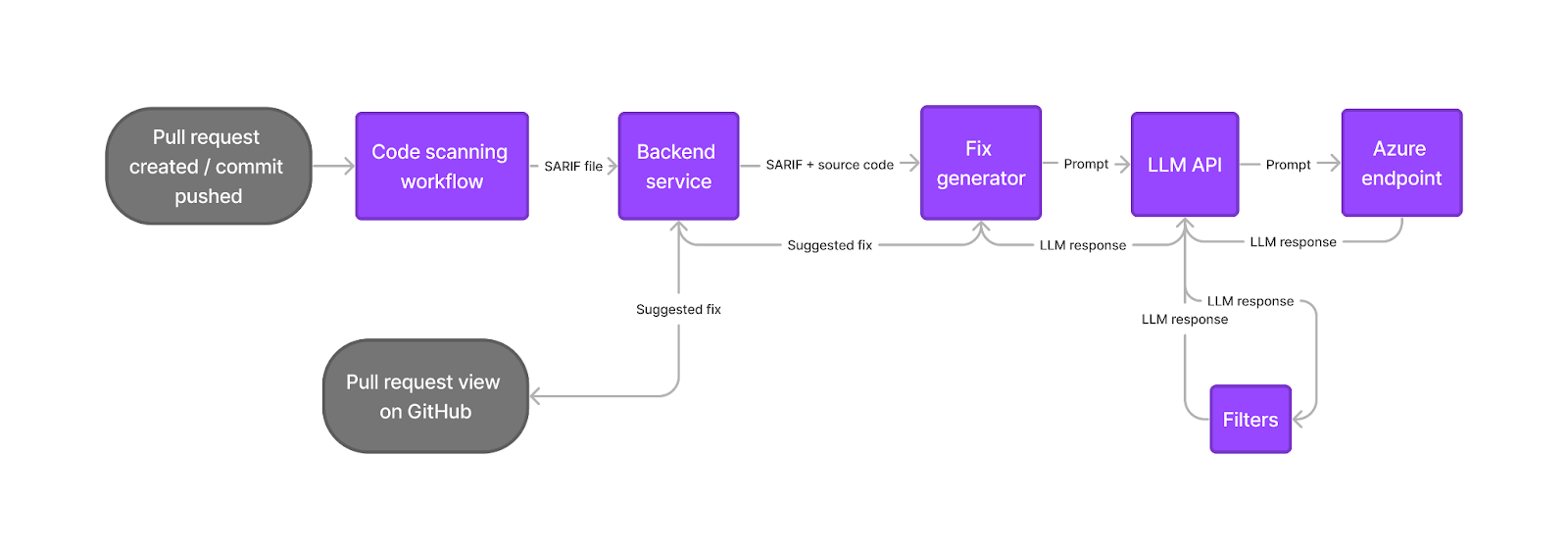
The user opens a pull request or pushes a commit. Code scanning runs as usual, as part of an actions workflow or workflow in a third-party CI system, uploading the results in the SARIF format to the code scanning API. The code scanning backend service checks whether the results are for a supported language. If so, it runs the fix generator as a CLI tool. The fix generator leverages the SARIF alert data, augmented with relevant pieces of source-code from the repository, to craft a prompt for the LLM. It calls the LLM via an authenticated API call to an internally-deployed API running LLMs on Azure. The LLM response is run through a filtering system which helps prevent certain classes of harmful responses. The fix generator then post-processes the LLM response to produce a fix suggestion. The code scanning backend stores the resulting suggestion, making it available for rendering alongside the alert in pull request views. Suggestions are cached for reuse where possible, reducing LLM compute requirements.
As with all GitHub products, we followed standard and internal security procedures, and put our architectural design through a rigorous security and privacy review process to safeguard our users. We also took precautions against AI-specific risks such as prompt injection attacks. While software security can never be fully guaranteed, we conducted red team testing to stress-test our model response filters and other safety mechanisms, assessing risks related to security, harmful content, and model bias.
Telemetry and monitoring
Before launching autofix, we wanted to ensure that we could monitor performance and measure its impact in the wild. We don’t collect the prompt or the model responses because these may contain private user code. Instead, we collect anonymized, aggregated telemetry on user interactions with suggested fixes, such as the percentage of alerts for which a fix suggestion was generated, the percentage of suggestions that were committed as-is to the branch, the percentage of suggestions that were applied through the GitHub CLI or Codespace, the percentage of suggestions that were dismissed, and the fix rate for alerts with suggestions versus alerts without. As we onboard more users onto the beta program, we’ll look at this telemetry to understand the usefulness of our suggestions.
Additionally, we’re monitoring the service for errors, such as overloading of the Azure model API or triggering of the filters that block harmful content. Before expanding autofix to unlimited public beta and eventually general availability, we want to ensure a consistent, stable user experience.
What’s next?
As we roll out the code scanning autofix beta to an increasing number of users, we’re collecting feedback, fixing papercuts, and monitoring metrics to ensure that our suggestions are in fact useful for security vulnerabilities in the wild. In parallel, we’re expanding autofix to more languages and use cases, and improving the user experience. If you want to join the public beta, sign up here. Keep an eye out for more updates soon!
Tags:
Written by

Related posts

How GitHub engineers tackle platform problems
Our best practices for quickly identifying, resolving, and preventing issues at scale.
GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it
Plus, considerations in updating one of GitHub’s oldest and most heavily used features.

Design system annotations, part 2: Advanced methods of annotating components
How to build custom annotations for your design system components or use Figma’s Code Connect to help capture important accessibility details before development.