Git’s database internals III: file history queries
Git’s file history queries use specialized algorithms that are tailored to common developer behavior. Level up your history spelunking skills by learning how different history modes behave and which ones to use when you need them.

This week, we are exploring Git’s internals with the following concept in mind:
Git is the distributed database at the core of your engineering system.
Before making a change to a large software system, it can be critical to understand the reasons why the code is in its current form. Looking at commit messages alone is insufficient for this discovery, and instead it is important to find the changes that modified a specific file or certain lines in that file. Git’s file history commands help users find these important points in time where changes were introduced.
Today, let’s dig into these different file history commands and consider them as a set of queries. We will learn how Git optimizes these queries based on the typical structure of file history and how merges work most of the time. Some additional history options may be required to discover what happened in certain special cases, such as using cherry-picks across multiple branches or mistakenly resolving merge conflicts incorrectly. Further, we will see some specialized data structures that accelerate these queries as repositories grow.
git log as file history
The primary way to discover which commits recently changed a file is to use git log -- <path>. This shows commits where their parent has a different Git object at <path>, but there are some subtleties as to which commits are shown, exactly.
One thing to keep in mind with file history queries is that the commit graph structure is still important. It is possible for two changes to happen in parallel and then be connected to the trunk through a merge. To help clarify what is happening with these queries, all examples in this section will assume that the --graph and --oneline options are also specified. The --graph option shows the relationships between commits and in particular will show when two commits are parallel to each other in the history. It also avoids interleaving two parallel sequences of commits that happen to have been created at the same time. I personally recommend that you use --graph whenever using these history walks.
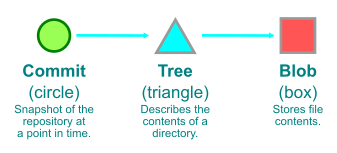
The most important thing to remember is that commits are snapshots, not diffs. For a quick refresher on how we represent Git objects, see the key below.
Git needs to dynamically compute the difference between two commits to see if <path> was changed. This means that Git loads the root trees for those two commits, then compares their tree entry for the first directory of <path> and compares the object ID found in each. This comparison is done recursively until equal object IDs are found (no difference) or all parts of <path> are walked and we find the two different objects at <path> for the two commits.

If we find equality during this process, we say that the two commits are treesame on this path.
For a commit with only one parent, we say that commit is interesting if it is not treesame. This is a natural idea, since this matches the only meaningful diff we could compute for that commit.
Similarly, a merge commit is considered interesting if it is not treesame to any of its parents. The figure below shows a number of interesting commits for a given path based on these treesame relationships.
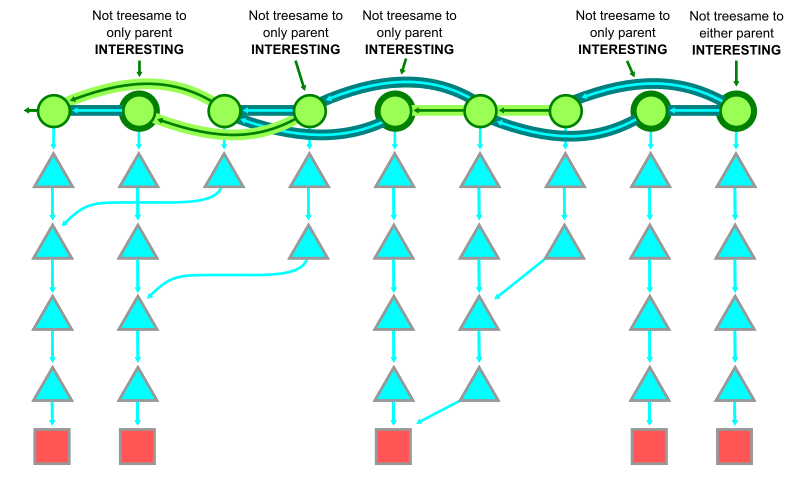
In the case of an uninteresting merge commit where there is at least one treesame parent, Git makes different decisions based on the history query type.
Simplified history
By default, git log -- <path> shows the simplified history of <path>. This is defined in the git log documentation, but I’ll present an alternative definition here.
When the simplified history mode encounters a merge commit, it compares the merge commit to each parent in order. If Git finds a treesame parent, then it stops computing diffs at the current merge, marks the merge as uninteresting, and moves on to that parent. If all parents are not treesame, then Git marks the merge as interesting and adds all parents to the walk.
For a path that is not changed very often, almost every merge commit will be treesame to its first parent. This allows Git to skip checking all of the commits made reachable by merges that did not “introduce” a change to the trunk. When a topic branch is merged into the trunk, the new merge commit rarely has any merge conflicts, so it will be treesame to its second parent for all the files that were changed in that topic. The merge would then not be treesame to its first parent on any of these paths.
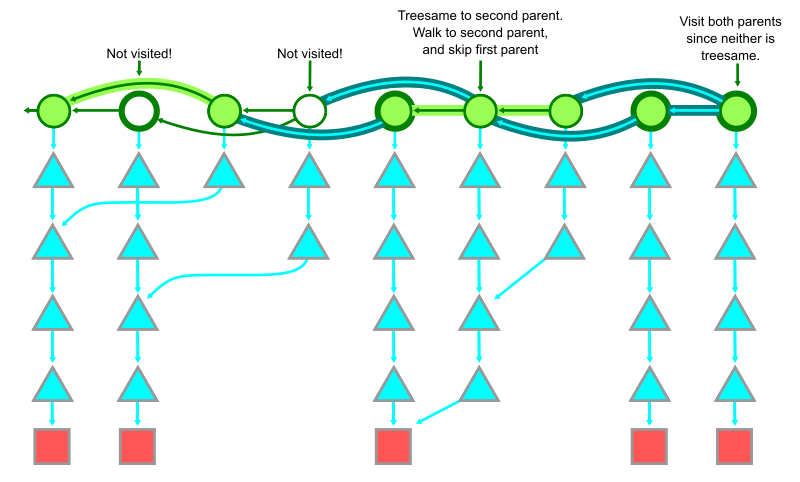
In the case that the merge commit is different from all of its parents on the path, then the merge is marked as interesting and all parents are added to the walk. This happens frequently when the path is a directory that has different sets of files change, but can also happen if the same file is modified by parallel changes and conflicts were resolved during the merge.
Here is an example query where two parallel topics both modified files inside the src/ directory:
$ git log --graph --oneline -- src/
* 80423fa Merge pull request #800 from ...
|\
| * 9313670 build(deps): bump Newtonsoft.Json in /src/shared/Core
* | 47ba58f diagnose: don't await Git exit on config list
|/
* 5637aa9 macos build: use runtime instead of osx-x64
* 7a99cc0 Fixes typo in Mac dist script
Note that the merge commits with a treesame parent are marked as uninteresting, even if they are different to their first parent. This means that the merge commit will not appear in the file history, even if it is responsible for introducing that change into the commit history. You can add the –show-pulls option to git log to make it output the merge commits that are different to their first parent. This can be particularly helpful if you are trying to also track which pull request was involved in that change.
Here is the output for the previous example, except that --show-pulls is added. Notice the additional “Merge pull request…” lines:
$ git log --graph --oneline --show-pulls -- src/
* 80423fa Merge pull request #800 from ...
|\
| * 9313670 build(deps): bump Newtonsoft.Json in /src/shared/Core
* | 77f7922 Merge pull request #804 from ...
* | 47ba58f diagnose: don't await Git exit on config list
|/
* b83bf02 Merge pull request #788 from ...
* 5637aa9 macos build: use runtime instead of osx-x64
* cf5a693 Merge pull request #778 from ...
* 7a99cc0 Fixes typo in Mac dist script
While this logic to skip huge chunks of history may seem confusing at first, it is a critical performance feature. It allows skipping commits that did not contribute to the latest version of the file. This works almost all of the time, but it is important to know some of the reasons why commits that might be interesting would be skipped by the simplified history mode.
Reverted Changes. Sometimes a pull request changes a file in its first version, but review feedback finds a different way to solve the problem without changing the file. The author might remove the changes to that file within their branch, but really has at least two commits editing the file. The end result makes no changes to the file since one commit reverts the previous changes. When that topic is merged, the merge commit is treesame to its first parent on that path and the topic branch is skipped.
Cherry-picks. Some bug fixes are critical to apply in multiple places, such as maintenance branches to solve security issues. If a commit is cherry-picked in multiple places, then it can look like “the same change” is happening in several parallel branches. If those branches eventually merge, they might merge automatically without conflict because all of the tips agree on the file contents. Thus, the simplified history walk will choose only one of these branches to walk and will discover one of the cherry-picks but not the others.
The previous two reasons are common but mostly harmless reasons why a commit could be skipped during simplified history. As someone who has worked on Git for several years, I can attest that the most common reason someone asks “what happened to my change?” is because of the more difficult third reason:
Merge conflict resolution. When resolving a merge, it is possible to make any number of mistakes. In particular, a common case is that someone gets confused and takes all of their changes and drops all changes from the other side of the merge. When this happens, simplified history works against us because Git sees a treesame parent and ignores the other side that had meaningful changes that were dropped by the merge conflict resolution.
These kinds of merge resolution issues are confusing on first glance, but we can use other history modes to discover what happened.
Full history
The --full-history mode changes from the simplified history mode by walking every commit in the history, regardless of treesame parents on merge commits. A merge commit is marked as interesting if there is at least one parent that is different at the path.
When used with --graph, Git performs parent rewriting to connect the parent links to the next interesting commit reachable from that parent. While the --full-history mode is sure to show all of the possible changes to the path, it is overly noisy. Here is the same repository used in the previous examples, but with --full-history we see many more merge commits:
$ git log --graph --oneline --full-history -- src/
* 5d869d9 Merge pull request #806 from ...
|\
* \ 80423fa Merge pull request #800 from ...
|\ \
| |/
|/|
| * 9313670 build(deps): bump Newtonsoft.Json in /src/shared/Core
* | 77f7922 Merge pull request #804 from ...
|\ \
| * | 47ba58f diagnose: don't await Git exit on config list
* | | 162d657 Merge pull request #803 from ...
|/ /
* / 10935fb Merge pull request #700 from ...
|/
* 2d79a03 Merge pull request #797 from ...
|\
* | e209b3d Merge pull request #790 from ...
|/
* b83bf02 Merge pull request #788 from ...
|\
| * 5637aa9 macos build: use runtime instead of osx-x64
Notice that these new merge commits have a second parent that wraps around and links back into the main history line. This is because that merge brought in a topic branch that did not change the src/ directory, but the first parent of the merge had some changes to the src/ directory relative to the base of the topic branch.
In this way, --full-history will show merges that bring in a topic branch whose history goes “around” meaningful changes. In a large repository, this noise can be so much that it is near impossible to find the important changes you are looking for.
The next history mode was invented to remove this extra noise.
Full history with simplified merges
In addition to --full-history, you can add the --simplify-merges option. This mode performs extra smoothing on the output of the --full-history mode, specifically dropping merge commits unless they actually are important for showing meaningful changes.
Recall from the --full-history example that some merge commits rewrote the second parent to be along the first-parent history. The --simplify-merges option starts by removing those parent connections and instead showing the merge as having a single parent. Then, Git inspects that commit as if it had a single parent from the beginning. If it is treesame to its only parent then that commit is removed. Git then rewrites any connections to that commit as going to its parent instead. This process continues until all simplifications are made, then the resulting history graph is shown.
$ git log --graph --oneline --full-history --simplify-merges -- src/
* 80423fa Merge pull request #800 from ...
|\
| * 9313670 build(deps): bump Newtonsoft.Json in /src/shared/Core
* | 47ba58f diagnose: don't await Git exit on config list
|/
* 5637aa9 macos build: use runtime instead of osx-x64
* 7a99cc0 Fixes typo in Mac dist script
Notice that this history is exactly the same as the simplified history example for this query. That is intentional: these should be the same results unless there really was an interesting change that was skipped.
If these history modes usually have the same output, then why wouldn’t we always use --full-history --simplify-merges? The reason is performance. Not only does simplified history speed up the query by skipping a large portion of commits, it also allows iterative output. The simplified history can output portions of the history without walking the entire history. By contrast, the --simplify-merges algorithm is defined recursively starting at commits with no parents. Git cannot output a single result until walking all reachable commits and computing their diffs on the input path. This can be extremely slow for large repositories.
One common complaint I have heard from Git users is “Git lost my change!” This typically takes the form where a developer knows that they merged in a commit that updated a file, but that change is no longer in the tip of that branch and running git log -- <path> does not show the commit they wrote! This kind of problem is due to file history simplification working as designed and skipping that commit, but it’s because someone created a faulty merge commit that is causing this unexpected behavior. If there is any chance that Git is skipping a commit that you know changed a file, then try to use --full-history with --simplify-merges.
To demonstrate, I took the previous example repository and created a branch that improperly resolved a merge to ignore valid changes that already existed in the trunk. Look carefully at the difference between the two history modes:
$ git log --graph --oneline -- src
* 5637aa9 macos build: use runtime instead of osx-x64
* 7a99cc0 Fixes typo in Mac dist script
$ git log --graph --oneline --full-history --simplify-merges -- src
* 7da271b Update with latest trunk
|\
| * 80423fa Merge pull request #800 from ...
| |\
| | * 9313670 build(deps): bump Newtonsoft.Json in /src/shared/Core
* | | 0b408b0 Resolve merge conflicts
|\| |
| |/
|/|
| * 47ba58f diagnose: don't await Git exit on config list
|/
* 5637aa9 macos build: use runtime instead of osx-x64
* 7a99cc0 Fixes typo in Mac dist script
When the actual history is shown, you can see that I created two “bad” merge commits: 7da271b Update with latest trunk and 0b408b0 Resolve merge conflicts. These both set the src directory equal to their first parents instead of allowing the merge to take the changes from both sides.
This history mode is a good tool to have in your arsenal.
Unfortunately, --full-history with --simplify-merges remains an expensive operation and I do not recommend using it by default. There remains no way to perform merge simplification without exploring the entire commit graph, even with the generation numbers discussed in part II. This remains an open problem, so if you have ideas about how to speed up this operation, then please bring those ideas to the Git developer community! I, for one, will be particularly interested!
Other history queries
Now that we’ve gone deep on the query modes for git log -- <path>, let’s consider a few other file history queries that shift the formula slightly in their own ways.
git log -L
The git log -L option allows specifying a portion of a file instead of an entire file. This helps you focus your history query to a specific function or set of lines. There are two main ways to use it:
git log -L<from>,<to>:<path>: In the file at<path>show any changes in the lines between<from>and<to>.git log -L:<identifier>:<path>: In the file at<path>, find the code associated with<identifier>and show any changes to those lines. Usually,<identifier>is a function name, but it can also refer to a class or struct.
The -L mode modifies the definition of “treesame” to also consider two versions of the file to be the same if they have the same content at these lines. Importantly, Git will track how the line numbers change as the line content stays the same, but other changes to earlier lines might add or delete lines to the file outside of this range. After that definition of treesame is updated, the history walk is the same as in the simplified history mode.
In this way, the -L mode is more expensive because it needs to compute blob content diffs instead of only comparing object IDs. However, that performance difference can be worthwhile, as it reduces your time spent reading changes to the file that are not important to the section of the file you are reading.
git blame and git annotate
While git log will show all the commits that have changed a given file, the git blame and git annotate commands show the commits that most-recently changed each line of the file. The only difference between the commands is the output style.
To compute these most-recent changes, Git tracks each line in a similar way as it does for git log -L, but then drops the line from consideration once it has found a commit that changed that line.
Speeding up file history queries
The previous sections detailed the types of file history queries available in Git. These queries are similar to the commit history queries from part II in that it helps to walk the commits more quickly. However, file history queries spend a significant amount of time testing treesame relationships by computing diffs.
Recall from part I that we can navigate to the Git object specified by a path at a given commit by following a sequence of object links:
- First, the commit has a root tree object ID that points to a tree object. The
commit-graphfile speeds this up slightly by including the root tree inside thecommit-graphfile instead of needing to parse the commit object directly. - Next, for each directory component in the path, Git parses a tree to find the matching tree entry and discovers the object ID of the next tree in the list.
- Finally, the last tree entry points to the object ID for the object at the path. This could be a tree or a blob object.
The git log -L and git blame queries go an additional step further by computing a content diff of two blobs. We will not focus on this part right now, because this only happens if the blobs are already different.
Structuring repositories for fast history queries
Git spends most of its time parsing trees to satisfy these file history queries. There are a few different dimensions in the structure of the repository that can affect how much time is spent parsing trees:
- Tree depth: The number of directories required to reach the specified path means that more trees need to be parsed before finding the object ID for that path. For example, Java namespaces are tied to the directory structure of the source files, so the tree depth tends to be high in these repositories.
- Adjacent changes: When comparing two commits at a given path, Git can walk both sides of the comparison at the same time. If two tree entries point to the same object ID at any point along the list of trees, then Git can stop parsing trees and determine the commits are treesame at the path. This happens less frequently if the path is in a directory full of other files that are changed often. For example, a
READMEfile for a subproject might be rarely changed, but lives next to the code for that project that changes frequently.
If you are making choices to structure your repository, you might notice that these two dimensions are competing with each other. If you try to reduce the tree depth by using wider directory structures, then you will create more frequent adjacent changes. In reality, a middle ground is best between the two extremes of a very wide or very deep repository.
The other way your repository structure can change the performance of file history queries is actually in the commit history itself. Some repositories require a linear history through rebases or squash-merges. These repositories do not gain any performance benefits from the commit-skipping feature of simplified file history. On the other hand, a linear history will have the exact same history output for all of the history modes, so there is no need to use the advanced modes.
Luckily, Git has a feature that can speed up these file history queries regardless of the repository shape.
Changed-path Bloom filters
To speed up file history queries, Git has an optional query index that allows it to skip parsing trees in the vast majority of cases.
The changed path Bloom filters index stores a data structure called a Bloom filter for every commit. This index is stored in the commit-graph file, so you can compute it yourself using the git commit-graph write --reachable --changed-paths command. Once the changed-path Bloom filters are enabled in your commit-graph, all future writes will update them. This includes the commit-graph writes done by background maintenance enabled by git maintenance start.
A commit’s Bloom filter is a probabilistic set. It stores the information for each path changed between the first parent and that commit. Instead of storing those paths as a list, the Bloom filter uses hash algorithms to flip a set of bits that look random, but are predictable for each input path.
This Bloom filter allows us to ask the question: Is a given path treesame between the first parent and this commit? The answer can be one of two options:
- Yes, probably different. In this case, we don’t know for sure that the path is different, so we need to parse trees to compute the diff.
- No, definitely treesame. In this case, we can trust the filter and continue along the first-parent history without parsing any trees.
The parameters of the Bloom filter are configured in such a way that a random treesame path has a 98% likelihood of being reported as definitely treesame by the filter.
While running git log -- <path>, Git is in simplified history mode and checks the first parent of each commit to see if it is treesame. If the changed-path Bloom filter reports that the commit is treesame, then Git ignores the other parents and moves to the next commit without parsing any trees! If <path> is infrequently changed, then almost all commits will be treesame to their first parents for <path> and the Bloom filters can save 98% of the tree-parsing time!
It is reasonable to consider the overhead of checking the Bloom filters. Fortunately, the filters use hash algorithms in such a way that it is possible to hash the input <path> value into a short list of integers once at the start of the query. The remaining effort is to load the filter from the commit-graph file, modulo those integers based on the size of the filter, then check if certain bits are set in the filter. In this way, a single key is being tested against multiple filters, which is a bit unusual compared to the typical application of Bloom filters.
Git also takes advantage of the directory structure of <path>. For example, if the path is given as A/B/C/d.txt, then any commit that changed this path also changed A, A/B, and A/B/C. All of these strings are stored in the changed-path Bloom filter. Thus, we can reduce the number of false positives by testing all of these paths against each filter. If any of these paths is reported as treesame, then the full path must also be treesame.
To test the performance of these different modes, I found a deep path in the Linux kernel repository that was infrequently changed, but some adjacent files are frequently changed: drivers/gpu/drm/i915/TODO.txt.
| Command | No commit-graph
|
No Bloom filters | Bloom filters |
git log -- <path>
|
1.03s | 0.67s | 0.18s |
git log --full-history -- <path>
|
17.8s | 11.0s | 3.81s |
git log --full-history --simplify-merges -- <path>
|
19.7s | 13.3s | 5.39s |
For queries such as git log -L and git blame, the changed-path Bloom filters only prevent that initial treesame check. When there is a difference between two commits, the content-based diff algorithm still needs to do the same amount of work. This means the performance improvements are more modest for these queries.
For this example, I used a path that is changed slightly more frequently than the previous one, but in the same directory: drivers/gpu/drm/i915/Makefile.
| Command | No commit-graph
|
No Bloom filters | Bloom filters |
git blame <path>
|
1.04s | 0.82s | 0.21s |
git log -L100,110:<path>
|
9.67s | 2.64s | 1.38s |
These performance gains are valuable for a normal user running Git commands in their terminal, but they are extremely important for Git hosting services such as GitHub that use these same Git history queries to power the web history interface. Computing the changed-path Bloom filters in advance can save thousands of CPU hours due to the frequency that users request this data from that centralized source.
Come back tomorrow for more!
Today, we went even deeper into Git’s internals and how its file history modes act as specialized queries into the commit history. Learning these advanced query types is similar to learning advanced language features of SQL such as different JOIN types. The commit-graph file again operated as a query index to accelerate these history queries.
In the next part of this blog series, we will explore how Git acts as a distributed database. Specifically, we will dig into how git fetch and git push help synchronize remote copies of a repository. The structure of the commit graph will be critical, but the cost of parsing trees will be even more immediate. We’ll talk about how reachability bitmaps can speed up some of these operations, but also explore some reasons why bitmaps are not always used.
I’ll also be speaking at Git Merge 2022 covering all five parts of this blog series, so I look forward to seeing you there!
Tags:
Written by

Related posts

From first commits to big ships: Tune into our new open source podcast
Introducing the brand new GitHub Podcast: A show dedicated to the topics, trends, stories, and culture in and around the open source developer community on GitHub.

Scaling for impact: How GitHub Copilot supercharges smallholder farmers
Empowering 10 million farm families by 2030 to generate $1 billion in new revenue. How GitHub helps One Acre Fund’s mission — driving real impact across Africa.
We need a European Sovereign Tech Fund
Open source software is critical infrastructure, but it’s underfunded. With a new feasibility study, GitHub’s developer policy team is building a coalition of policymakers and industry to close the maintenance funding gap.