Highlights from Git 2.33
The open source Git project just released Git 2.33, with features and bug fixes from over 74 contributors. Here’s a look at some of the most interesting features and changes.

The open source Git project just released Git 2.33 with features and bug fixes from over 74 contributors, 19 of them new. We last caught up with you on the latest in Git when 2.31 was released. Here’s a look at some of the most interesting features and changes since then.
Geometric repacking
In a previous blog post, we discussed how GitHub was using a new mode of git repack to implement our repository maintenance jobs. In Git 2.32, many of those patches were released in the open-source Git project. So, in case you haven’t read our earlier blog post, or just need a refresher, here are some details on geometric repacking.
Historically, git repack did one of two things: it either repacked all loose objects into a new pack (optionally deleting the loose copies of each of those objects), or it repacked all packs together into a single, new pack (optionally deleting the redundant packs).
Generally speaking, Git has better performance when there are fewer packs, since many operations scale with the number of packs in a repository. So it’s often a good idea to pack everything together into one single pack. But historically speaking, busy repositories often require that all of their contents be packed together into a single, enormous pack. That’s because reachability bitmaps, which are a critical optimization for server-side Git performance, can only describe the objects in a single pack. So if you want to use bitmaps to effectively cover many objects in your repository, those objects have to be stored together in the same pack.
We’re working toward removing that limitation (you can read more about how we’ve done that), but one important step along the way is to implement a new repacking scheme that trades off between having a relatively small number of packs, and packing together recently added objects (in other words, approximating the new objects added since the previous repack).
To do that, Git learned a new “geometric” repacking strategy. The idea is to determine a (small-ish) set of packs which could be combined together so that the remaining packs form a geometric progression based on object size. In other words, if the smallest pack has N objects, then the next-largest pack would have at least 2N objects, and so on, doubling (or growing by an arbitrary constant) at each step along the way.
To better understand how this works, let’s work through an example on seven packs. First, Git orders all packs (represented below by a green or red square) in ascending order based on the number of objects they contain (the numbers inside each square). Then, adjacent packs are compared (starting with the largest packs and working toward the smaller ones) to ensure that a geometric progression exists:
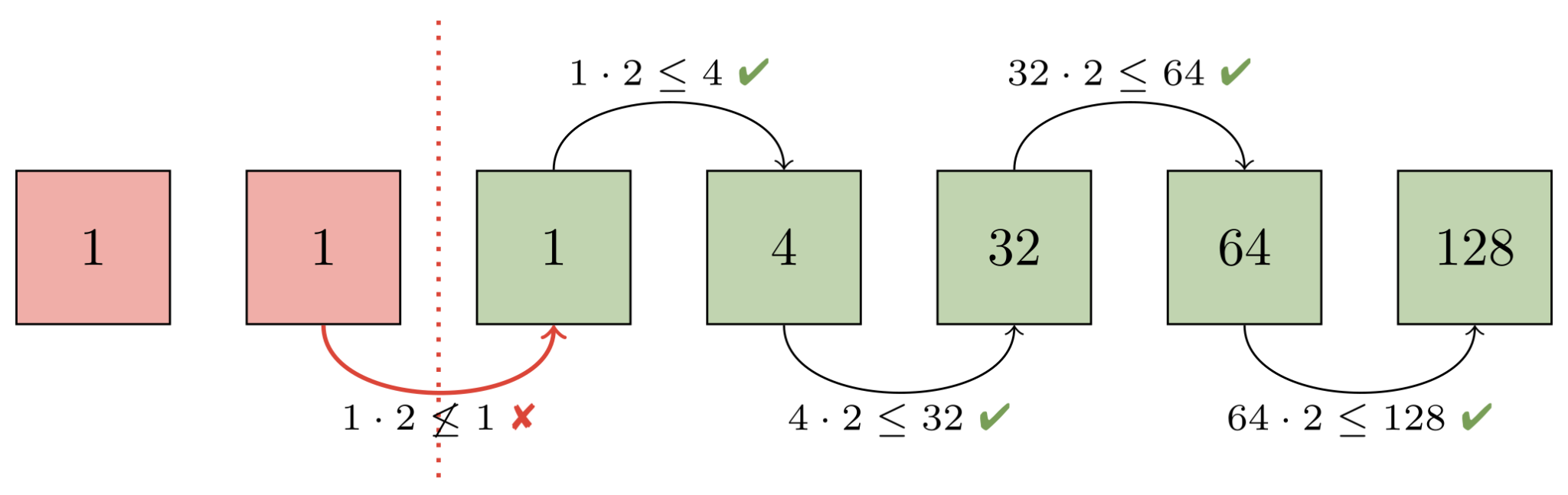
Here, the progression is broken between the second and third pack. That’s because both of those packs each have the same number of objects (in this case, just one). Git then decides that at least the first two packs will be contained in a new pack which is designed to restore the geometric progression. It then needs to figure out how many larger packs must also get rolled up in order to maintain the progression:
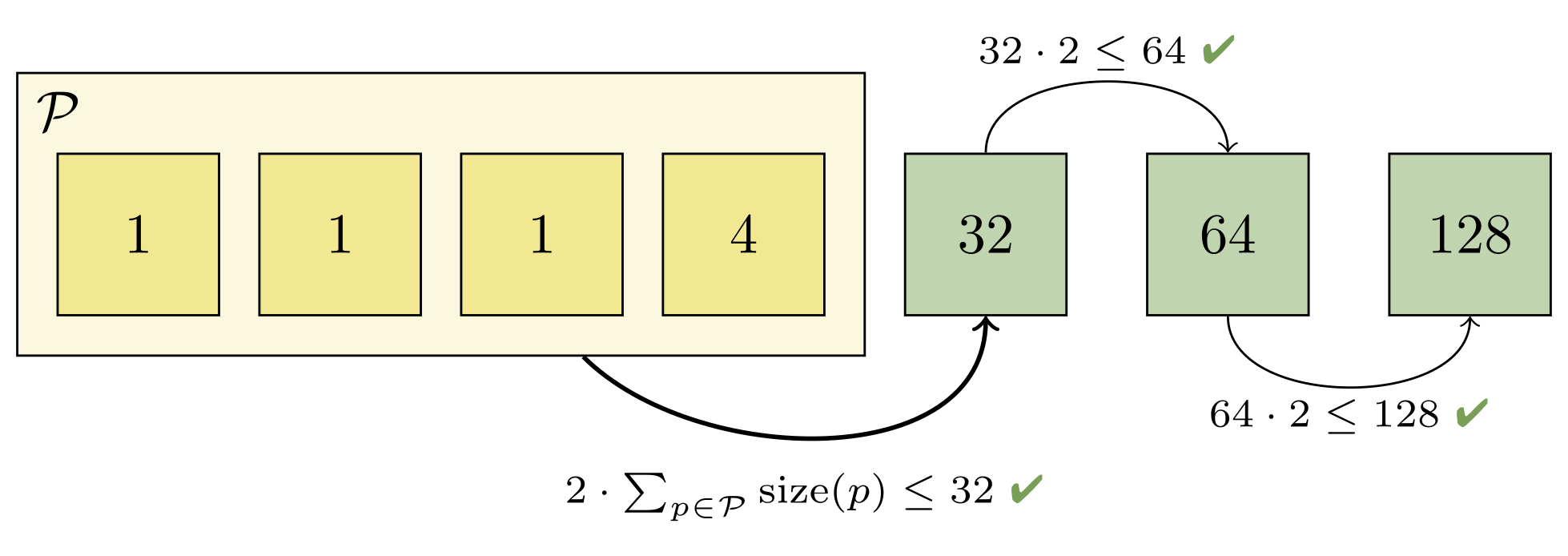
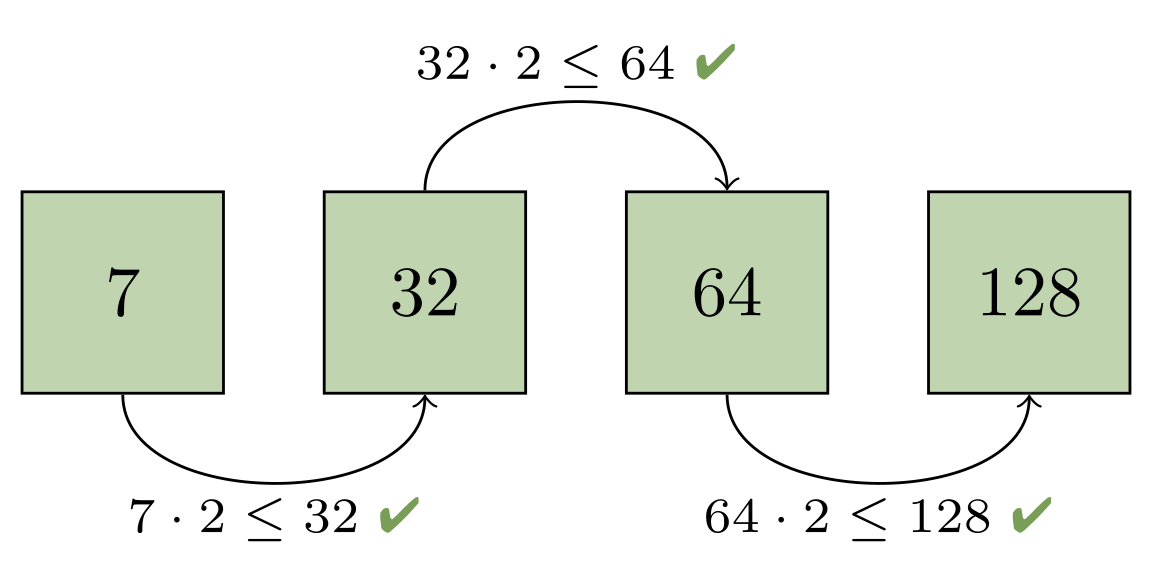
Combining the first two packs would give us two objects, which would still be too large to fit into the progression (since the next largest pack only has one object). But rolling up the first four packs is sufficient, since the fifth pack contains more than twice as many objects as the first four packs combined:
You can try this out yourself by comparing the pack sizes on a repository on your laptop before and after geometric repacking with the following script:
$ packsizes() {
find .git/objects/pack -type f -name '*.pack' |
while read pack; do
printf "%7d %s\n" \
"$(git show-index < ${pack%.pack}.idx | wc -l)" "$pack"
done | sort -rn
}
$ packsizes # before
$ git repack --geometric=2 -d
$ packsizes # after
We have also contributed patches to write the new on-disk reverse index format for multi-pack indexes. This format will ultimately be used to power multi-pack bitmaps by allowing Git to map bit positions back to objects in a multi-pack index.
Together, these two features will make it possible to cover the objects in the resulting packs with a reachability bitmap, even when there’s more than one pack remaining. Those patches are still being polished and reviewed, but expect an update from us when they’re incorporated into a release.
merge-ort: a new merge strategy
When Git performs a merge between two branches, it uses one of several “strategy” backends to resolve the changes. The original strategy is simply called resolve and does a standard three-way merge. But that default was replaced early in Git’s history by merge-recursive, which had two important advantages:
- In the case of “criss-cross” merges (where there is not a single
common point of divergence between two branches), the strategy
performs a series of merges (recursively, hence the name) for each
possible base. This can resolve cases for which theresolve
strategy would produce a conflict. -
It detects file-level renames along each branch. A file that was
modified on one side but renamed on the other will have its
modifications applied to the renamed destination (rather than
producing a very confusing conflict).
merge-recursive served well as Git’s default for many years, but it had a few shortcomings. It was originally written as an external Python script which used Git’s plumbing commands to examine the data. This was later rewritten in C, which provided a speed boost. But its code organization and data structures still reflected its origins: it still operated primarily on Git’s “index” (the on-disk area where changes are collected for new commits) and the working tree.
This resulted in several bugs over the years around tricky corner cases (for example, this one or some of these).
merge-recursive‘s origins also made it harder to optimize and extend the code. Merge time isn’t a bottleneck in most workflows, but there are certainly large cases (especially involving renames) where merge-recursive could be very slow. Likewise, the merge backend is used for many operations that combine two sets of changes. A cherry-pick or rebase operation may perform a series of merges, and speeding them up has a noticeable effect.
The merge-ort strategy is a from-scratch rewrite with the same concepts (recursion and rename-detection), but solving many of the long-standing correctness and performance problems. The result is much faster. For a merge (but a large, tricky one containing many renames), merge-ort gains over a 500x speedup. For a series of similar merges in a rebase operation, the speedup is over 9000x (because merge-ort is able to cache and reuse some computation common to the merges). These cases were selected as particularly bad for the merge-recursive algorithm, but in our testing of typical cases we find that merge-ort is always a bit faster than merge-recursive. The real win is that merge-ort consistently performs at that fast speed while merge-recursive has high variance.
On top of that, the resulting code is cleaner and easier to work with. It fixes some known bugs in merge-recursive. It’s more careful about not accessing unchanged parts of the tree, meaning that people working with partial clones should be able to complete more merges without having to download extra objects. And because it doesn’t rely on the index or working tree while performing the merge, it will open up new opportunities for tools like git log to show merges (for example, a diff between the vanilla merge result and the final committed state, which shows how the author resolved any conflicts).
The new merge-ort is likely to become the default strategy in a future version of Git. In the meantime, you can try it out by running git merge -s ort or setting your pull.twohead config to ort (despite the name, this is used for any merge, not just git pull). You might not see all of the same speedups yet; some of them will require changes to other parts of Git (for example, rebase helping pass the cached data between each individual merge).
Rather than link to the source commits, of which there are over 150 spread across more than a dozen branches, check out this summary from the author on the mailing list. Or if you want to go in-depth, check out his series of blog posts diving into the rationale and the details of various optimizations:
part 1
part 2
part 3
part 4
part 5
All that
Per our usual style, we like to cover two or three items from recent releases in detail, and then a dozen or so smaller topics in lesser detail. Now that we’ve gotten the former out of the way, here’s a selection of interesting changes in Git 2.32 and 2.33:
- You might have used
git rev-listto drive Git’s history traversal machinery.
It can be really useful when scripting, especially if you need to list the
commits/objects between two endpoints of history.git rev-listhas a very handy--prettyflag which allows it to format the
commits it encounters.--prettycan display information about a commit
(such as its author, author date, hash, parts of its message, and so on). But it can be difficult to use when scripting. Say you want the list of days that you wrote commits. You might think to run something like:$ git rev-list --format=%as --author=peff HEAD | head -4 commit 27f45ccf336d70e9078075eb963fb92541da8690 2021-07-26 commit 8231c841ff7f213a86aa1fa890ea213f2dc630be 2021-07-26(Here, we’re just asking
rev-listto show the author date of each commit
written by @peff.) But what are those lines interspersed withcommit?
That’s due to a historical quirk whererev-listfirst writes a line
containingcommit <hash>before displaying a commit with--pretty.
In order to keep backwards compatibility with existing scripts, the
quirk must remain.In Git 2.33, you can specify
--no-commit-headerto opt out of this
historical design decision, which makes scripting the above much easier:
[source]
-
Here’s a piece of Git trivia: say you wanted to list all blobs smaller than 200 bytes. You might consider using
rev-list‘s--filterfeature (the same mechanism that powers partial clones) to accomplish this. But what would you expect the following to print?$ git rev-list --objects --no-object-names \ --filter=blob:limit=200 v2.32.0..v2.33.0 \ | git cat-file --batch-check='%(objecttype)' | sort -u(In this example, we’re asking
rev-listto list all objects introduced
since version 2.32, filtering all blobs which are larger than 200 bytes.
Then, we askcat-fileto print out the types of all of those objects and
list the unique values).If you expected just “blob,” you’d be wrong! The
--filter=blob:limit=200
only filters blobs. It doesn’t stoprev-listfrom printing non-blob objects.In Git 2.32, you can solve this problem by excluding the blobs with a new
--filter=object:type=<type>filter. Since multiple--filters are combined together by taking the union of their results, this does the trick:$ git rev-list --objects --no-object-names \ --filter=object:type=blob \ --filter=blob:limit=200 \ --filter-provided-objects v2.32.0..v2.33.0 \ | git cat-file --batch-check='%(objecttype)' | sort -u blob(Here,
--filter-provided-objectsallowsrev-listto apply the same
filters to the tips of its traversal, which are exempt from filtering by
default).[source]
-
You might be aware of
git log‘s “decorate” feature, which adds output to
certain commits indicating which references point at them. For example:$ git log --oneline --decorate | head -1 2d755dfac9 (HEAD -> master, tag: v2.33.0-rc1, origin/master, origin/HEAD) Git 2.33-rc1By default, Git loads these decorations if the output is going to a terminal or if
--decoratewas given. But loading these decorations can be wasteful in examples like these:$ git log --graph --decorate --format='%h %s' | head -1 2d755dfac9 Git 2.33-rc1Here, Git would have wasted time loading all references since
--decorate
was given but its--formatdoesn’t cause any decoration information to be
written to the output.Git 2.33 learned how to detect if loading reference decorations will be useful (if they will show up in the output at all), and it optimizes the loading process to do as little work as possible even when we are showing decorations, but the decorated object does not appear in the output.
[source]
-
Speaking of
git log --formatplaceholders, Git 2.32 comes with a couple of
new ones. You can now display the author and committer date in the “human” format (which we talked about when it was introduced back in Git 2.21) with%ahand%ch.The new
%(describe)placeholder makes it possible to include the output of
git describealongside commits displayed in the log. You can use%(describe)to get the bare output ofgit describeon each line, or you can write%(describe:match=<foo>,exclude=<bar>)to control the--matchand--excludeoptions. -
Have you ever been working on a series of patches and realized that you
forgot to make a change a couple of commits back? If you have, you might
have been tempted toresetback to that point, make your changes, and then
cherry-pickthe remaining commits back on top.There’s a better way: if you make changes directly in your working copy
(even after you wrote more patches on top), you can make a special “fixup”
commit with thegit commit --fixupoption. This option creates a new
commit with the changes that you meant to apply earlier. Then, when you
rebase, Git automatically sequences the fixup commit in the right place and
squashes its contents back where you originally wanted them.But what if instead of changing the contents of your patch, you wanted to
change the log message itself? In Git 2.32,git commitlearned a new
--fixup=(amend|reword):<commit>option, which allows you to tweak the
behavior of--fixup. With--fixup=amend, Git will replace the log
message and the patch contents with your new one, all without you having to
pause your workflow to rebase.
If you use
--fixup=rewordinstead, you can tell Git to just replace the
log message while leaving the contents of the reworded patch untouched.[source]
-
You might be familiar with Git’s “trailers” mechanism, the structured
information that can sometimes appear at the end of a commit. For example, you might have seen trailers used to indicate the Developer’s Certificate of Origin at the end of a commit withSigned-off-by. Or perhaps you have seen projects indicate who reviewed what withReviewed-by.These trailers are typically written by hand when crafting a commit message
in your editor. But now Git can insert these trailers itself via the new
--trailerflag when runninggit commit. Trailers are automatically
inserted in the right place so that Git can parse them later on. This can be
especially powerful with the new--fixupoptions we just talked about. For
example, to add missing trailers to a commit,foo:$ git commit --no-edit \ --fixup=reword:foo \ --trailer='Signed-off-by=Mona Lisa Octocat <mona@github.com>' $ EDITOR=true git rebase -i --autosquash foo^[source]
-
Here’s the first of two checkout-related tidbits. Git uses the
git checkoutprogram to update your working copy (that is, the actual files on disk that you read/edit/compile) to match a particular state in history. Until very recently,git checkoutworked by creating, modifying, or removing files and directories one-by-one.When spinning-disk drives were more common, any performance improvement that
could be had by parallelizing this process would have been negligible, since
hard-disk drives are more frequently I/O-bound than more modern solid-state
and NVMe-based drives.(Of course, this is a little bit of an over-simplification: sometimes having
more tasks gives the I/O scheduler more items to work with, which actually
can help most on a spinning disks, since requests can be ordered by platter
location. It’s for this reason that Git refreshes the index using parallel
lstat()threads.)In Git 2.32,
git checkoutlearned how to update the working copy in
parallel by dividing the updates it needs to execute into different groups,
then delegating each group to a worker process. There are two knobs to
tweak:checkout.workersconfigures how many workers to use when updating the
tree (and you can use ‘0’ to indicate that it should use as many workers
as there are logical CPU cores).-
checkout.thresholdForParallelismconfigures how many updates are
necessary before Git kicks in the parallel code paths over the
sequential ones.
Together, these can provide substantial speed-ups when checking out repositories in different environments, as demonstrated here.
-
In an earlier blog post, Derrick Stolee talked about sparse checkouts. The goal of sparse checkout is to make it feel like the repository you’re working in is small, no matter how large it actually is.
Even though sparse checkouts shrink your working copy (that is, the number of files and directories which are created on disk), the index–the data structure Git uses to create commits–has historically tracked every file in the repository, not just those in your sparse checkout. This makes operations that require the index slow in sparse checkouts, even when the checkout is small, since Git has to compute and rewrite the entire index for operations which modify the index.
Git 2.32 has updated many of the index internals to only keep track of files in the sparse checkout and any directories at the boundary of the sparse checkout when operating in cone mode.
Different commands that interact with the index each have their own
assumptions about how the index should work, and so they are in the process
of being updated one-by-one. So far,git checkout,git commit, andgithave been updated, and more commands are coming soon.
statusYou can enable the sparse index in your repository by enabling the
index.sparseconfiguration variable. But note, while this feature is still
being developed it’s possible that Git will want to convert the sparse index
to a full one on the fly, which can be slower than the original operation you were performing. In future releases, fewer commands will exhibit this behavior until all index-related commands are converted over. -
Here’s a short and sweet one from 2.32: a new
SECURITY.mddocument was introduced to explain how to securely report vulnerabilities in Git. Most importantly, the email address of the security-focused mailing list (git-security@googlegroups.com) is listed more prominently. (For the extra-curious, the details of how embargoed security releases are coordinated and distributed are covered as well.)[source]
Finally, a number of bitmap-related optimizations were made in the last couple
of releases. Here are just a few:
- When using reachability bitmaps to serve, say, a fetch request, Git marks
objects which the client already has as “uninteresting,” meaning that they
don’t need to be sent again. But until recently, if a tag was marked as
uninteresting, the object being pointed at was not also marked as
uninteresting.Because the haves and wants are combined with an
AND NOT, this bug didn’t
impact correctness. But it can cause Git to waste CPU cycles since it can
cause full-blown object walks when the objects that should have been marked
as uninteresting are outside of the bitmap. Git 2.32 fixes this bug by
propagating the uninteresting status of tags down to their tagged objects.[source]
-
Some internal Git processes have to build their own reachability bitmaps on
the fly (like when an existing bitmap provides complete coverage
up to the most recent branches and tags, so a supplemental bitmap must be
generated and thenOR‘d in). When building these on-the-fly bitmaps, we
can avoid traversing into commits which are already in the bitmap, since we
know all of the objects reachable from that commit will also be in the
bitmap, too.But we don’t do the same thing for trees. Usually this isn’t a big deal.
Root trees are often not shared between multiple commits, so the
walk is often worthwhile. But traversing into shared sub-trees is wasteful
if those sub-trees have already been seen (since we know all of their
reachable objects have also been seen).Git 2.33 implements the same optimization we have for skipping already-seen
commits for trees, too, which has provided some substantial speed-ups,
especially for server-side operations.[source]
-
When generating a pack while using reachability bitmaps, Git will try to
send a region from the beginning of an existing packfile more-or-less
verbatim. But there was a bug in the “Enumerating objects” progress meter
that caused the server to briefly flash the number of reused objects and
then reset the count back to zero before counting the objects it would
actually pack itself.This bug was somewhat difficult to catch or notice because the pack reuse
mechanism only recently became more aggressive, and because you have to see it at exactly the right moment in your terminal to notice.But regardless, this bug has been corrected, so now you’ll see an accurate
progress meter in your terminal, no matter how hard you stare at it.[source]
…And a bag of chips
That’s just a sample of changes from the latest couple of releases. For more, check out the release notes for 2.32 and 2.33, or any previous version in the Git repository.
Tags:
Written by

Related posts

From first commits to big ships: Tune into our new open source podcast
Introducing the brand new GitHub Podcast: A show dedicated to the topics, trends, stories, and culture in and around the open source developer community on GitHub.

Scaling for impact: How GitHub Copilot supercharges smallholder farmers
Empowering 10 million farm families by 2030 to generate $1 billion in new revenue. How GitHub helps One Acre Fund’s mission — driving real impact across Africa.
We need a European Sovereign Tech Fund
Open source software is critical infrastructure, but it’s underfunded. With a new feasibility study, GitHub’s developer policy team is building a coalition of policymakers and industry to close the maintenance funding gap.