DNS Outage Post Mortem
Last week on Wednesday, January 8th, GitHub experienced an outage of our DNS infrastructure. As a result of this outage, our customers experienced 42 minutes of downtime of services along…
Last week on Wednesday, January 8th, GitHub experienced an outage of our DNS infrastructure. As a result of this outage, our customers experienced 42 minutes of downtime of services along with an additional 1 hour and 35 minutes of downtime within a subset of repositories as we worked to restore full service. I would like apologize to our customers for the impact to your daily operations as a result of this outage. Unplanned downtime of any length is unacceptable to us. In this case we fell short of both our customers’ expectations and our own. For that, I am truly sorry.
I would like to take a moment and explain what caused the outage, what happened during the outage, and what we are doing to help prevent events like this in the future.
Some background…
For some time we’ve been working to identify places in our infrastructure that are vulnerable to Distributed Denial of Service (DDoS) attacks. One of the things we specifically investigated was options for improving our defenses against DNS amplification attacks, which have become very common across the internet. In order to simplify our access control rules, we decided to reduce the number of hosts which are allowed to make DNS requests and receive DNS replies to a very small number of name servers. This change allows us to explicitly reject DNS traffic that we receive for any address that isn’t explicitly whitelisted, reducing our potential attack surface area.
What happened…
In order to roll out these changes, we had prepared changes to our firewall and router configuration to update the IP addresses our name servers used to send queries and receive responses. In addition, we prepared similar changes to our DNS server configuration to allow them to use these new IP addresses. The plan was to roll out this set of changes for one of our name servers, validate the new configuration worked as expected, and proceed to make the same change to the second server.
Our rollout began on the afternoon of the 8th at 13:20 PM PST. Changes were deployed to the first DNS server, and an initial verification led us to believe the changes had been rolled out successfully. We proceeded to deploy to the second name server at 13:29 PM PST, and again performed the same verification. However, problems began manifesting nearly immediately.
We began to observe that certain DNS queries were timing out. We quickly investigated, and discovered a bug in our rollout procedure. We expected that when our change was applied, both our caching name servers and authoritative name servers would receive updated configuration – including their new IP addresses – and restart to apply this configuration. Both name servers received the appropriate configuration changes, but only the authoritative name server was restarted due to a bug in our Puppet manifests. As a result, our caching name server was requesting authoritative DNS records from an IP that was no longer serving DNS. This bug created the initial connection timeouts we observed, and began a cascade of events.
Our caching and authoritative name servers were reloaded at 13:49 PST, resolving DNS query timeouts. However, we observed that certain queries were now incorrectly returning NXDOMAIN. Further investigation found that our DNS zone files had become corrupted due to a circular dependency between our internal provisioning service and DNS.
During the investigation of the first phase of this incident, we triggered a deployment of our DNS system, which performs an API call against our internal provisioning system and uses the result of this call to construct a zone file. However, this query requires a functioning DNS infrastructure to complete successfully. Further, the output from this API call verification was not adequately checked for sanity before being converted into a zone file. As a result, this deployment removed a significant amount of records from our name servers, causing the NXDOMAIN results we observed. The missing DNS records were restored by performing the API call manually, validating the output, and updating the affected zones.
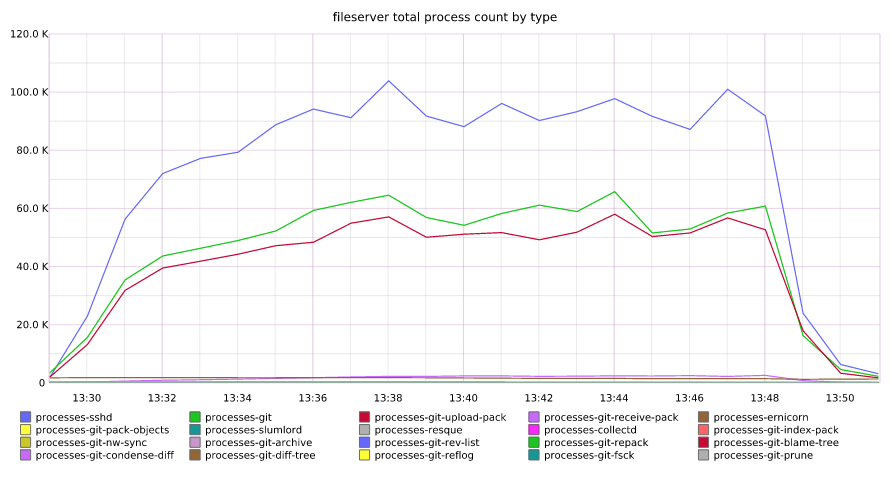
Many of our servers recovered gracefully once DNS service began responding appropriately. However, we quickly noted that github.com performance had not returned to normal, and our error rates were far higher than normal. Further investigation found that a subset of our fileservers were actively refusing connections due to what we found out later was memory exhaustion, exacerbated by the spawning of a significant number of processes on during the DNS outage.
Total number of processes across fileservers
Total memory footprint across fileservers
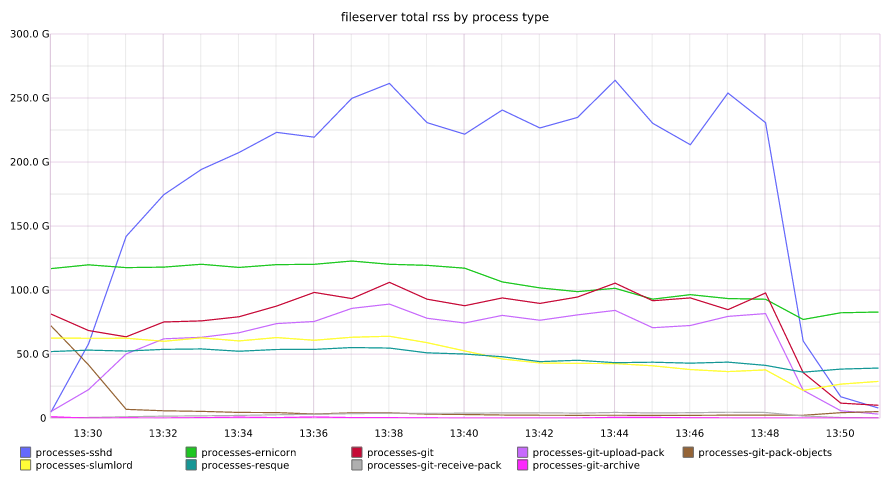
The failing fileservers began creating a back pressure in our routing layer that prevented connections to healthy fileservers. Our team began manually removing all misbehaving fileservers from the routing layer, restoring services for the fileservers that had survived the spike in processes and memory during the DNS event.
The team split up the pool of disabled fileserver, and triaged their status. Collectively, we found one of two scenarios existed to be repaired: either the node had calmed down ‘enough’ as a result of DNS service restoration to allow one of our engineers to log into the box and start forcefully killing hung processes to restore service, or the node had become so exhausted that our HA daemon kicked in to STONITH the active node and bring up our secondary node. In both of these situations, our team went in and performed checks against our low-level DRBD block devices to ensure there were no inconsistencies or errors in data replication. Full service was restored for all of our customers by 15:47 PM PST.
What we’re doing about it…
This small problem uncovered quite a bit about our infrastructure that we will be critically reviewing over the next few weeks. This includes:
- We are investigating further decoupling of our internal and external DNS infrastructure. While the pattern of forwarding requests to an upstream DNS server is not uncommon, the tight dependency that exists between our internal name servers and our external name servers needs to be broken up to allow changes to happen independently of each other.
- We are reviewing our configuration management code for other service restart bugs. In many cases, this means the improvement of our backend testing. We will be reviewing critical code for appropriate tests using
rspec-puppet, as well as looking at integration tests to ensure that service management behaves as intended. - We are reviewing the cyclic dependency between our internal provisioning system and our DNS resolvers, and have already updated the deployment procedure to verify the results returned from the API call before removing a large number of records.
- We are reviewing and testing all of the designed safety release valves in our fileserver management systems and routing layers. During the failure when filesevers became so exhausted that the routing layer failed due to back pressure, we should have seen several protective measures kick in to automatically remove these servers from service. These mechanisms did not fire off as designed, and need to be revisited.
- We are implementing process accounting controls to appropriately limit the resources consumed by our application processes. Specifically, we are testing Linux
cgroupsto further isolate application processes from administrative system functionality. In the event of a similar event in the future, this should allow us to restore full access much more quickly. - We are reviewing the code deployed to our fileservers to analyze for tight dependencies to DNS. We reviewed the DNS time-outs on our fileservers and found that DNS requests should have timed out after 1 second, and only retried to resolve 2 times in total. This analysis along with cgroup implementation should provide a better barrier to avoid runaway processes in the first place, and a safety valve to manage them if processing becomes unruly in the future.
Summary
We realize that GitHub is an important part of your development and workflow. Again, I would like to take a moment to apologize for the impact that this outage had to your operations. We take great pride in providing the best possible service quality to our customers. Occasionally, we run into problems as detailed above. These incidents further drive us to continually improve the quality of our own internal operations and ensure that we are living up to the trust you have placed in us. We are working diligently to provide you with a stable, fast, and pleasant GitHub experience. Thank you for your continual support of GitHub!
Written by

Related posts

Apply now for GitHub Universe 2023 micro-mentoring
As part of our ongoing commitment to accelerate human progress through Social Impact initiatives, we’re offering students 30-minute, 1:1 micro-mentoring sessions with GitHub employees ahead of Universe.

The 2023 Open Source Program Office (OSPO) Survey is live!
Help quantify the state of enterprise open source by taking the 2023 OSPO survey.

Godot 4.0 Release Party 🎉
We are delighted to host the Godot 4.0 Release Party at GitHub HQ on Wednesday, March 22 from 6:30 pm to 9:30 pm. And you’re invited!